Python pour le développement de l’IA : Guide complet du débutant 2026

⏱ 25 minutes de lecture · Catégorie : Développement de l’IA
Présentation
Python est le langage de l’IA. Des laboratoires de recherche d’OpenAI aux systèmes de production de Google, Python est le moteur de la révolution de l’IA. Si vous souhaitez créer des applications d’IA, Python n’est pas négociable.
Mais apprendre Python pour l’IA n’est pas comme apprendre Python pour le développement Web. Vous avez besoin de bibliothèques, de frameworks et de modèles mentaux spécifiques. La plupart des débutants commencent par des cours théoriques et se perdent dans les mathématiques avant d’écrire une seule ligne de code produisant de vrais résultats.
Ce guide adopte une approche différente. Vous apprendrez Python pour l’IA de la même manière que les professionnels construisent des systèmes : pratique, axé sur le projet, avec juste assez de théorie pour comprendre ce qui se passe sous le capot.
À la fin, vous comprendrez l’écosystème d’IA de Python, écrirez du code fonctionnel qui utilise l’apprentissage automatique et les API d’IA, et disposerez d’une feuille de route réaliste vers les compétences en IA.
Statistique clé : les développeurs qui apprennent en construisant mettent 6 à 12 mois pour atteindre leurs compétences professionnelles. Ceux qui se concentrent sur les cours prennent d’abord 18 à 24 mois. La différence ? Application immédiate.
Table des matières
- Pourquoi Python pour l’IA : l’avantage de l’écosystème
- Configuration de votre environnement de développement Python IA
- Concepts de base de Python pour l’IA
- Bibliothèques Python essentielles pour l’IA
- Cadres d’apprentissage profond : PyTorch vs TensorFlow
- Travailler avec des modèles pré-entraînés
- Création de votre première application d’IA
- LangChain : créer des agents intelligents
- Préparation et prétraitement des données
- Du prototype à la production
- Pièges courants et comment les éviter
- FAQ
Pourquoi Python pour l’IA : l’avantage de l’écosystème
Python n’est pas le langage le plus rapide. Ce n’est pas le plus élégant. Mais elle domine l’IA pour une raison : l’écosystème.
L’écosystème
Tous les principaux frameworks d’IA donnent la priorité à Python :
- PyTorch : recherche et production de deep learning
- TensorFlow : machine learning évolutif à l’échelle de l’entreprise
- Hugging Face : plus d’un million de modèles pré-entraînés pour le texte, la vision et l’audio
- LangChain : Créer des agents intelligents avec des LLM
- SDK OpenAI Python : API officielles pour GPT-4, intégrations et bien plus encore
Lorsqu’une nouvelle avancée se produit dans l’IA (une nouvelle architecture de modèle, une nouvelle technique de formation), la première implémentation se fait toujours en Python.
La communauté
La communauté de l’IA privilégie Python. Réponses Stack Overflow, projets GitHub, documents de recherche avec code : ils sont tous Python. Lorsque vous êtes bloqué, l’aide est abondante.
La courbe vitesse-prototype
Python sacrifie la vitesse d’exécution au profit de la vitesse de développement. Une tâche prenant des semaines en Java prend des jours en Python. Pour l’IA, ce compromis en vaut la peine. Vous consacrez 90 % de votre temps aux algorithmes et à l’architecture, et 10 % à l’optimisation des performances.
Configuration de votre environnement de développement Python AI

Vous n’avez pas besoin de matériel coûteux pour démarrer. Un ordinateur portable MacBook ou Windows convient parfaitement. Si vous disposez d’un GPU (de préférence NVIDIA), c’est encore mieux, mais ce n’est pas obligatoire pour l’apprentissage.
Étape 1 : Installer Python
Téléchargez Python 3.12 ou 3.13, 3.14 depuis python.org. Évitez la version 3.15+ (trop récente, certains packages sont en retard).
# Vérifier l'installation
python --version
# Devrait afficher : Python 3.12.x ou 3.14.xÉtape 2 : Créer un environnement virtuel
N’installez jamais de packages globalement. Utilisez toujours des environnements virtuels.
# Créer un environnement
python -m venv myai_env
# Activer (Mac/Linux)
source myai_env/bin/activate
# Activer (Windows)
myai_env\Scripts\activate
# Votre terminal devrait maintenant afficher (myai_env)Étape 3 : Installer les packages essentiels
pip install numpy pandas matplotlib scikit-learn jupyterÉtape 4 : Installer AI Frameworks
Pour apprendre, commencez par PyTorch (plus facile pour les débutants) :
# Version du processeur (recommandé pour les débutants)
pip installer la torche torchvision torchaudio
# Version du GPU (si vous disposez d'un GPU NVIDIA)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118Étape 5 : Configurez votre IDE
Utilisez soit :
- VS Code + extension Python (gratuite, recommandée)
- Communauté PyCharm (fonctionnalités gratuites spécifiques à l’IA)
- Curseur (codage assisté par IA, 20 $/mois)
Étape 6 : Vérifier la configuration
python -c "import torch; print(torch.__version__)"Vous devriez voir un numéro de version imprimé.
À retenir : la configuration de l’environnement prend 30 minutes. Investissez ce temps une fois : vous gagnerez des heures plus tard.
Concepts de base de Python pour l’IA

Vous n’avez pas besoin d’être un expert Python. Vous devez comprendre ces cinq concepts :
Concept 1 : Variables et types
# Numéros
âge = 25 # entier
hauteur = 5,9 # flotteur
note = 98,5
# Chaînes
nom = "Alice"
message = f"Bonjour, {name}" # f-strings pour le formatage
# Listes (ordonnées, modifiables)
nombres = [1, 2, 3, 4, 5]
nombres.append(6)
# Dictionnaires (paires clé-valeur)
personne = {"nom": "Alice", "âge": 25, "ville": "NYC"}
print(person["name"]) # Accès : AliceConcept 2 : Fonctions
def greet(nom) :
return f"Bonjour, {nom} !"
result = greet("Alice") # Les fonctions prennent une entrée, renvoient une sortieConcept 3 : Bibliothèques et importations
# Importer la bibliothèque entière
importer numpy en tant que np
# Importer une fonction spécifique
à partir de dateheure importer dateheure
# Utilisez ce que vous avez importé
array = np.array([1, 2, 3, 4, 5])
maintenant = datetime.now()Concept 4 : Compréhensions de listes (abréviation Python)
# Boucle traditionnelle
au carré = []
pour le nombre en [1, 2, 3, 4, 5] :
au carré.append(nombre ** 2)
# Façon pythonique
au carré = [numéro ** 2 pour le nombre dans [1, 2, 3, 4, 5]]
# Les deux produisent : [1, 4, 9, 16, 25]Concept 5 : Gestion des erreurs
essayez :
résultat = 10 / 0 # Cela échouera
sauf ZeroDivisionError :
print("Impossible de diviser par zéro !")
enfin :
print("Le code de nettoyage s'exécute indépendamment")À retenir : Maîtrisez ces cinq concepts et vous pourrez écrire 80 % du code d’IA que vous rencontrerez.
Bibliothèques Python essentielles pour l’IA
NumPy : La Fondation
NumPy crée des tableaux et des matrices : la structure de données de toute IA.
importer numpy en tant que np
# Créer des tableaux
array = np.array([1, 2, 3, 4, 5])
matrice = np.array([[1, 2, 3], [4, 5, 6]])
# Opérations sur les tableaux
moyenne = np.mean(array) # Moyenne
std = np.std(array) # Écart type
normalisé = (tableau - moyenne) / std # NormaliserPandas : manipulation de données
Pandas gère le chargement, le nettoyage et l’exploration des données.
importer des pandas au format PD
# Charger le CSV
df = pd.read_csv('data.csv')
# Explorer
df.head() # 5 premières lignes
df.describe() # Statistiques
df.info() # Types de données et valeurs manquantes
# Nettoyer
df = df.dropna() # Supprime les valeurs manquantes
df['age'] = df['age'].astype(int) # Convertir les types
# Filtre
young_people = df[df['age'] < 30]Matplotlib et Seaborn : visualisation
Vous ne pouvez pas déboguer ce que vous ne pouvez pas voir.
importer matplotlib.pyplot en tant que plt
importer Seaborn en tant que SNS
# Tracé linéaire
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
# Histogramme
sns.histplot(data=df, x='age', bacs=20)
plt.show()Scikit-Learn : ML classique
Pour les tâches ne nécessitant pas d’apprentissage en profondeur, scikit-learn est le plus rapide.
depuis sklearn.linear_model import LinearRegression
depuis sklearn.model_selection importer train_test_split
# Fractionner les données
X_train, X_test, y_train, y_test = train_test_split(
fonctionnalités, étiquettes, test_size=0.2
)
# Modèle de train
modèle = Régression Linéaire()
modèle.fit (X_train, y_train)
# Évaluer
score = model.score(X_test, y_test)Cadres d’apprentissage profond : PyTorch vs TensorFlow
Les deux sont excellents. PyTorch est plus convivial pour les débutants. TensorFlow est plus adapté à l’échelle de production.
PyTorch : le choix de la recherche
Le code PyTorch se lit comme du Python classique. Les erreurs sont claires. La courbe d’apprentissage est douce.
importer la torche
importer torch.nn en tant que nn
# Créer un réseau de neurones simple
classe SimpleNet(nn.Module) :
def __init__(soi) :
super().__init__()
self.fc1 = nn.Linear(784, 128) # 784 entrées → 128 neurones
self.fc2 = nn.Linear(128, 10) # 128 neurones → 10 sorties
def forward(soi, x) :
x = torche.relu(self.fc1(x))
x = soi.fc2(x)
retourner x
# Instancier
modèle = SimpleNet()
# Passe avant
input_data = torch.randn(32, 784) # 32 échantillons, 784 fonctionnalités
sortie = modèle (input_data)TensorFlow : le choix de production
TensorFlow s’adapte à des ensembles de données et à des GPU volumineux. Plus de cérémonie, mais plus de contrôle.
importer Tensorflow au format TF
# Créer un modèle
modèle = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)),
tf.keras.layers.Dense(10, activation='softmax')
])
# Compiler
modèle.compile(
optimiseur='adam',
loss='sparse_categorical_crossentropy',
metrics=['précision']
)
# Former
model.fit(X_train, y_train, époques=10)À retenir : Commencez avec PyTorch pour apprendre. Passez à TensorFlow si vous devez déployer à l’échelle de l’entreprise.
Travailler avec des modèles pré-entraînés
La formation de modèles à partir de zéro est lente et coûteuse. Les modèles pré-entraînés sont beaucoup plus rapides.
Transformateurs de visage câlins
Hugging Face héberge plus d’un million de modèles open source.
à partir du pipeline d'importation des transformateurs
# Génération de texte
générateur = pipeline('text-génération', modèle='gpt2')
résultat = générateur('Il était une fois', max_length=50)
imprimer(résultat)
# Analyse des sentiments
classificateur = pipeline('analyse-sentiment')
result = classifier("J'adore ce film !")
# Sortie : [{'label' : 'POSITIVE', 'score' : 0,9999}]
# Reconnaissance d'entité nommée
ner = pipeline('ner')
result = ner("Apple Inc a son siège à Cupertino, en Californie")
# Extrait les organisations, les emplacements, les personnesAPI OpenAI (GPT-4, intégrations)
Les modèles les plus puissants sont accessibles via API.
depuis openai import OpenAI
client = OpenAI(api_key="votre-api-key")
# Générer du texte
réponse = client.chat.completions.create(
modèle="gpt-4",
messages=[
{"role": "user", "content": "Expliquez l'informatique quantique en 2 phrases"}
]
)
print(response.choices[0].message.content)Ajustement précis des modèles pré-entraînés
Adaptez les modèles à votre domaine spécifique.
depuis l'importation des transformateurs Formateur, TrainingArguments
training_args = TrainingArguments(
rép_sortie='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
)
entraîneur = Entraîneur (
modèle = modèle,
args=entraînement_args,
train_dataset=train_dataset,
)
entraîneur.train()Créer votre première application d’IA
Créons un analyseur de sentiments qui classe les critiques de films.
Étape 1 : Obtenir des données
importer des pandas au format PD
# Charger des exemples de données
données = {
'révision' : [
'Ce film est incroyable !',
"Terrible perte de temps",
"Pas mal, ça vaut le coup d'être regardé"
],
'sentiment' : ['positif', 'négatif', 'positif']
}
df = pd.DataFrame(données)Étape 2 : Charger le modèle pré-entraîné
à partir du pipeline d'importation des transformateurs
classifier = pipeline('analyse-sentiment')Étape 3 : faire des prédictions
reviews = df['review'].tolist()
prédictions = classificateur (avis)
# Ajouter au cadre de données
df['predicted_sentiment'] = [
pred['label'].lower() pour pred dans les prédictions
]
imprimer(df)Étape 4 : Évaluer
# Comparez les prévisions et les réalités
précision = (df['sentiment'] == df['predicted_sentiment']).mean()
print(f"Précision : {précision :.2%}")À retenir : L’ensemble de ce flux de travail (charger des données, faire des prédictions, évaluer) a nécessité 20 lignes de code. C’est toute la puissance des modèles pré-entraînés.
LangChain : créer des agents intelligents
LangChain connecte les LLM à des outils externes. Cela permet aux agents de rechercher sur le Web, de lire des PDF et d’exécuter du code.
Chaîne LLM de base
depuis langchain.chat_models importer ChatOpenAI
à partir de langchain.prompts, importez ChatPromptTemplate
llm = ChatOpenAI(model="gpt-4", température=0)
# Créer une invite
prompt = ChatPromptTemplate.from_messages([
("utilisateur", "Expliquez {sujet} en 2 phrases")
])
# Créer une chaîne
chaîne = invite | llm
# Exécuter
résultat = chain.invoke({"topic": "machine learning"})
print(result.content)Agent avec outils
depuis langchain.agents import initialize_agent, outil
à partir de l'outil d'importation langchain.tools
depuis langchain.chat_models importer ChatOpenAI
@outil
def calculatrice(expression : str) -> str :
"""Évalue les expressions mathématiques"""
return str(eval(expression))
@outil
def web_search(requête : str) -> str :
"""Recherche sur le Web"""
# Implémenter avec la bibliothèque de requêtes
return f "Résultats pour {requête}"
tools = [calculatrice, web_search]
llm = ChatOpenAI(model="gpt-4")
agent = initialize_agent(tools, llm, agent="zero-shot-react-description")
result = agent.run("Qu'est-ce que 2+2 ? Ensuite recherchez la capitale de la France")Cet agent choisit les outils à utiliser et dans quel ordre, en toute autonomie.
Préparation et prétraitement des données
La plupart des projets d’IA consacrent 70 % de leur temps à la préparation des données. Apprenez cette compétence très tôt.
Chargement des données
importer des pandas au format PD
# CSV
df = pd.read_csv('data.csv')
# JSON
df = pd.read_json('data.json')
# Base de données SQL
importer sqlite3
conn = sqlite3.connect('base de données.db')
df = pd.read_sql('SELECT * FROM table', conn)Nettoyage des données
# Supprimer les valeurs manquantes
df = df.dropna()
# Remplir les valeurs manquantes
df['age'].fillna(df['age'].mean(), inplace=True)
# Supprimer les doublons
df = df.drop_duplicates()
# Supprimer les valeurs aberrantes (valeurs au-delà de 3 développements standard)
df = df[
(df['age'] > df['age'].mean() - 3 * df['age'].std()) &
(df['age'] < df['age'].mean() + 3 * df['age'].std())
]Ingénierie des fonctionnalités
# Créer de nouvelles fonctionnalités
df['age_squared'] = df['age'] ** 2
df['age_category'] = pd.cut(df['age'], bins=[0, 18, 65, 100])
# Encoder les variables catégorielles
df = pd.get_dummies(df, colonnes=['city'])
# Mettre à l'échelle les caractéristiques numériques
à partir de sklearn.preprocessing importer StandardScaler
scaler = StandardScaler()
df[['age', 'revenu']] = scaler.fit_transform(df[['age', 'revenu']])Du prototype à la production
Le passage des notebooks Jupyter à la production nécessite une certaine structure.
Structure du projet
my_ai_project/
├── données/
│ ├── cru/
│ └── traité/
├── modèles/
│ └── trained_model.pkl
├── cahiers/
│ └── exploration.ipynb
├──src/
│ ├── __init__.py
│ ├── data_loader.py
│ ├── modèle.py
│ └── prédire.py
├── exigences.txt
└── README.mdExemple de script de production
# src/predict.py
cornichon d'importation
importer des pandas en tant que PD
classe ModelPipeline :
def __init__(self, model_path) :
avec open(model_path, 'rb') comme f :
self.model = pickle.load(f)
def prédire (self, input_data) :
"""input_data : pandas DataFrame"""
prédictions = self.model.predict (input_data)
prédictions de retour
si __name__ == '__main__' :
pipeline = ModelPipeline('models/trained_model.pkl')
test_data = pd.read_csv('data/processed/test.csv')
prédictions = pipeline.predict (test_data)
print(prédictions)Déploiement avec FastAPI
depuis l'importation fastapi FastAPI
à partir de l'importation pydantique BaseModel
cornichon d'importation
application = FastAPI()
# Charger le modèle une fois au démarrage
avec open('models/trained_model.pkl', 'rb') comme f :
modèle = pickle.load(f)
classe PredictionRequest (BaseModel) :
âge : entier
revenu : flottant
@app.post("/predict")
def prédire (requête : PredictionRequest) :
prédiction = model.predict([[request.age, request. Income]])
return {"prédiction": float(prédiction[0])}
# Exécuter : uvicorn app:app --reloadPièges courants et comment les éviter
Piège 1 : passer directement au Deep Learning
L’apprentissage profond est puissant mais excessif pour la plupart des problèmes. Essayez d’abord scikit-learn.
Correction : la régression linéaire, les forêts aléatoires et l’augmentation du gradient résolvent 80 % des problèmes sans apprentissage profond.
Piège 2 : Travailler sans contrôle de version
Vous répéterez constamment. Suivez votre travail.
Correction : utilisez Git dès le premier jour. Poussez vers GitHub.
git init
git ajouter .
git commit -m "Commit initial"
git push origin principalPiège 3 : ne pas documenter le code
Vous oublierez ce que vous avez écrit dans 2 semaines.
Correction : Ajouter des docstrings aux fonctions :
def predict_sentiment(texte) :
"""
Classez le sentiment du texte comme positif ou négatif.
Args :
text (str) : Le texte à classer
Retours :
str : « positif » ou « négatif »
"""
# Implémentation
renvoyer le résultatPiège 4 : s’entraîner sur toutes vos données
Vous ne pouvez pas évaluer les données sur lesquelles vous vous êtes entraîné. Réservez toujours les données de test.
Correction : Divisez vos données :
depuis sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0,2, random_state=42
)Piège 5 : ignorer le déséquilibre des données
Si vous prédisez une fraude (0,1 % des cas), un modèle prédisant « pas de fraude » ; est toujours précis à 99,9 % mais inutile.
Correction : utilisez des métriques appropriées (score F1, AUC-ROC) et des techniques de rééchantillonnage.
FAQ
Q : Combien de temps faut-il pour apprendre Python pour l’IA ?
6 à 12 mois de pratique constante pour atteindre la compétence professionnelle. Plus rapide si vous créez des projets immédiatement. Plus lent si vous regardez des cours sans coder.
Q : Ai-je besoin d’un GPU ?
Non, pas pour commencer. Un processeur d’ordinateur portable moderne convient parfaitement à l’apprentissage. Le GPU accélère la formation pour les grands modèles (bénéfique une fois que vous comprenez les bases).
Q : Dois-je d’abord apprendre les mathématiques ou le codage ?
Codage d’abord. Apprenez les mathématiques au fur et à mesure que vous les rencontrez. La théorie sans pratique est vite oubliée.
Q : Quel est le meilleur ordre pour apprendre les bibliothèques ?
NumPy → Pandas → Matplotlib → Scikit-Learn → PyTorch (ou TensorFlow) → LangChain.
Q : Comment puis-je savoir si je suis prêt pour la production ?
Vous êtes prêt quand vous le pouvez :
1. Chargez et nettoyez les données de manière indépendante
2. Entraîner un modèle sans copier-coller de code
3. Évaluez les performances avec des mesures appropriées
4. Déployez sur une API simple
Q : Dois-je utiliser Jupyter ou VS Code ?
Les deux. Jupyter pour l’exploration et l’apprentissage. VS Code pour les projets destinés à la production.
Q : Comment puis-je rester informé face à l’évolution rapide de l’IA ?
Suivez : Papers with Code, Hugging Face Blog, forums fast.ai. Créez des projets à l’aide de nouveaux outils : c’est l’apprentissage le plus rapide.
Bibliothèques Python avancées pour le développement de l’IA
PyTorch pour le Deep Learning
PyTorch est le framework préféré pour l’IA de recherche et de production. Il est pythonique, flexible et largement adopté par les principales équipes d’IA de Meta, Tesla et OpenAI.
importer la torche
importer torch.nn en tant que nn
à partir de torch.utils.data importer DataLoader, TensorDataset
classe SimpleNet(nn.Module) :
def __init__(self, input_size, Hidden_size, Output_size) :
super(SimpleNet, soi).__init__()
self.fc1 = nn.Linear (input_size, Hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, sortie_size)
def forward(soi, x) :
x = soi.fc1(x)
x = soi.relu(x)
x = soi.fc2(x)
retourner x
modèle = SimpleNet(10, 64, 2)
loss_fn = nn.CrossEntropyLoss()
optimiseur = torch.optim.Adam(model.parameters(), lr=0.001)
pour l'époque dans la plage (100) :
sorties = modèle (X_train)
perte = perte_fn (sorties, y_train)
optimiseur.zero_grad()
perte.backward()
optimiseur.step()À retenir : PyTorch permet une expérimentation rapide. Modifiez les architectures et les fonctions de perte avec seulement quelques lignes de code.
LangChain pour les applications LLM
LangChain simplifie la création d’applications sur des modèles de langage tels que GPT-4. Il gère les invites, les chaînes, la mémoire et les intégrations.
à partir de langchain importer OpenAI, LLMChain, PromptTemplate
llm = OpenAI(api_key="sk-...", température=0,7)
template = "Vous êtes un assistant IA utile. Question de l'utilisateur : {question}. Réponse utile :"
prompt = PromptTemplate(input_variables=["question"], template=template)
chaîne = LLMChain (llm=llm, invite=invite)
result = chain.run("Qu'est-ce que l'apprentissage automatique ?")
imprimer(résultat)Utilisez LangChain pour : les chatbots, les réponses aux questions, les résumés et les chaînes de raisonnement en plusieurs étapes.
Bases de données vectorielles : Pinecone et Weaviate
Pour les applications d’IA utilisant des intégrations, les bases de données vectorielles stockent et interrogent efficacement les intégrations.
importer une pomme de pin
Pinecone.init(api_key="...", environnement="us-west1-gcp")
index = pomme de pin.Index("documents")
intégrations = [[0,1, 0,2, 0,3], [0,4, 0,5, 0,6]]
identifiants = ["doc1", "doc2"]
index.upsert(vecteurs=liste(zip(identifiants, intégrations)))
query_embedding = [0,15, 0,25, 0,35]
résultats = index.query(query_embedding, top_k=5)Les bases de données vectorielles alimentent les systèmes de recommandation, la recherche sémantique et la génération augmentée par récupération.
Déployer des modèles d’IA en production
Conteneurisation avec Docker
Docker regroupe votre code et vos dépendances dans un conteneur cohérent.
DEpuis python:3.11-slim
RÉPERT TRAVAIL /app
COPIER exigences.txt .
EXÉCUTER pip install -r exigences.txt
COPIE . .
CMD ["python", "app.py"]Construire et exécuter :
docker build -t my-ai-app:1.0 .
docker run -p 8000:8000 mon-ai-app:1.0Docker garantit que votre modèle fonctionne de manière identique en développement, en test et en production.
Déploiement d’API avec FastAPI
FastAPI est rapide et moderne pour servir des modèles d’IA.
depuis l'importation fastapi FastAPI
à partir de l'importation pydantique BaseModel
importer joblib
application = FastAPI()
modèle = joblib.load("model.pkl")
classe PredictionRequest (BaseModel) :
fonctionnalités : liste
@app.post("/predict")
def prédire (requête : PredictionRequest) :
prédiction = model.predict([request.features])[0]
return {"prediction": prédiction}Démarrez le serveur :
pip installer fastapi uvicorn
application uvicorn :app --host 0.0.0.0 --port 8000N’importe quelle application peut désormais appeler votre modèle : POST http://localhost:8000/predict
Plateformes de déploiement (2026)
Hugging Face Spaces – Gratuit pour les modèles open source. Facile à partager et à démo.
AWS SageMaker – Niveau entreprise avec mise à l’échelle, surveillance et gestion des versions.
Render ou Railway – Déploiement simple et bon marché. Commencez à 7 $/mois.
Google Cloud Run – Paiement à la demande, pas de serveur. Idéal pour les charges de travail variables.
Vercel – Idéal pour le frontend et l’IA. Expédiez des applications full-stack en quelques minutes.
Test du code IA
Modèles de tests unitaires
Testez les prédictions de votre modèle avec des entrées connues.
importer le test unitaire
importer numpy en tant que np
classe TestModel (unittest.TestCase):
def setUp (auto):
self.model = load_model("chemin/vers/modèle")
def test_prediction_shape(self):
X = np.array([[1, 2, 3], [4, 5, 6]])
y = self.model.predict(X)
self.assertEqual(y.shape, (2, 1))
def test_prediction_range(self):
X = np.array([[1, 2, 3]])
y = self.model.predict(X)[0]
self.assertTrue(0 <= y <= 1)
si __name__ == '__main__' :
unittest.main()Surveillance des performances du modèle
Surveillez la précision du modèle, la latence et la dérive des données en production.
à partir de sklearn.metrics import précision_score
journalisation des importations
enregistreur = journalisation.getLogger(__name__)
def monitor_predictions (true_labels, prédictions) :
précision = précision_score (true_labels, prédictions)
logger.info(f"Précision du modèle : {précision :.4f}")
si précision < 0,85 :
logger.warning("Précision du modèle inférieure au seuil !")
précision du retourErreurs courantes de développement de l’IA
Erreur 1 : fuite de données
Problème : Les données de test incluent accidentellement des informations provenant des données d’entraînement.
# FAUX
X_normalized = normaliser (X)
X_train, X_test = train_test_split (X_normalisé)
# CORRECT
X_train, X_test, y_train, y_test = train_test_split(X, y)
X_train = normaliser (X_train)
X_test = normaliser(X_test)Erreur 2 : surapprentissage sur de petits ensembles de données
Utilisez la régularisation et la validation croisée.
depuis sklearn.model_selection import cross_val_score
à partir de sklearn.linear_model importer LogisticRegression
scores = cross_val_score(LogisticRegression(C=1.0), X, y, cv=5)
print(f"Précision du CV : {scores.mean():.4f} (+/- {scores.std():.4f})")Erreur 3 : Utilisation de la mauvaise métrique
Pour les ensembles de données déséquilibrés, utilisez F1 ou précision équilibrée au lieu de précision.
à partir de sklearn.metrics import f1_score, Balanced_accuracy_score
f1 = f1_score(y_true, y_pred)
Balanced_acc = Balanced_accuracy_score (y_true, y_pred)Erreur 4 : non gestion des données manquantes
depuis sklearn.impute importer SimpleImputer
imputer = SimpleImputer(stratégie="moyenne")
X_imputed = imputer.fit_transform(X)Idées de projets d’IA pour l’apprentissage
Projet 1 : Chatbot d’analyse des sentiments (débutant – 2 semaines)
Créez un chatbot qui classe les sentiments et répond.
Outils : Transformers, FastAPI, Gradio
Étapes : (1) Utiliser le modèle de sentiment Hugging Face (2) Créer un point de terminaison FastAPI (3) Créer une interface utilisateur Gradio (4) Déployer sur les espaces Hugging Face
Compétences : Modèle d’API, déploiement, intégration d’interface utilisateur
Projet 2 : Moteur de recommandation (Intermédiaire – 4 semaines)
Créez un outil de recommandation de films à l’aide du filtrage collaboratif.
Outils : LightFM, Pandas, PostgreSQL
Étapes : (1) Obtenir un ensemble de données de recommandation (2) Créer un modèle de filtrage collaboratif (3) Créer une API (4) Déployer sur AWS/Render
Compétences : Systèmes de recommandation, requêtes de bases de données, conception d’API
Projet 3 : Système de questions et réponses sur les documents (avancé – 6 semaines)
Créez un système qui répond aux questions sur vos documents à l’aide de RAG.
Outils : LangChain, OpenAI, Pinecone, FastAPI
Étapes : (1) Charger et fragmenter des documents (2) Générer des intégrations, les stocker dans Pinecone (3) Récupérer des fragments pour les questions des utilisateurs, appeler LLM (4) Déployer en tant qu’application Web
Compétences : LLM, plongements, recherche de vecteurs, déploiement en production
Chemin de carrière : de débutant à ingénieur en IA
Mois 1 à 3 : Fondations
Focus : Bases de Python, fondamentaux du ML, premiers modèles
Action : Cours Python (2 à 3 semaines) → NumPy, Pandas (2 semaines) → projet scikit-learn (2 semaines)
Résultat : Créer des modèles simples de classification/régression
Perspectives d’emploi : Ingénieur ML junior, analyste de données (60 à 80 000 $)
Mois 4 à 6 : Deep Learning
Focus : Réseaux de neurones, PyTorch, modèles image/NLP
Action : Théorie des réseaux neuronaux (2 semaines) → PyTorch CNN (3 semaines) → Transformateurs NLP (2 semaines)
Résultat : Former et déployer des modèles de Deep Learning
Perspectives d’emploi : ingénieur ML, ingénieur IA (120 à 160 000 $)
Mois 7 à 12 : production et amp; Spécialisation
Focus : Déploiement, LLM, mise à l’échelle, spécialisation
Action : Choisir une spécialisation (CV/NLP/recommandations) → Créer 2 à 3 projets de portefeuille → Déployer en production → Contribuer à l’open source
Résultat : Envoyer les produits d’IA en production
Perspectives d’emploi : Ingénieur ML senior, ingénieur produit IA (150 à 250 000 $ et plus)
Au-delà de l’année 1 : maîtrise et amp; Direction
Options :
– Chercheur : finalité doctorat, laboratoires FAANG (180 – 300 000 $+)
– Fondateur de startup : Créer un produit d’IA (0 à 10 millions de dollars et plus, risque élevé)
– Architecte IA : Diriger les stratégies d’IA d’entreprise (200 à 400 000 $)
– Scientifique en IA : Modèles Frontier (200 à 500 000 $ et plus)
Clé : Créez de vrais projets, expédiez-les en production, comprenez l’impact commercial.
Applications d’IA : exemples Python du monde réel
Exemple 1 : Créer un chatbot simple avec LangChain
Voici un chatbot complet qui mémorise le contexte de la conversation :
depuis langchain.llms importer OpenAI
à partir de langchain.memory importer ConversationBufferMemory
à partir de langchain.chains importer ConversationChain
mémoire = ConversationBufferMemory()
llm = OpenAI(api_key="sk-...")
conversation = ConversationChain (llm=llm, mémoire=mémoire)
tandis que Vrai :
user_input = input("Vous : ")
réponse = conversation.run(input=user_input)
print(f"Bot : {response}")Ce chatbot conserve automatiquement l’historique des conversations. Le ConversationBufferMemory stocke l’intégralité de la conversation, de sorte que le modèle dispose d’un contexte pour les questions de suivi.
Exemple 2 : Classification d’images avec un visage câlin
Classer des images sans entraîner de modèle :
à partir du pipeline d'importation des transformateurs
classificateur = pipeline("classification d'images",
modèle="google/vit-base-patch16-224")
résultat = classificateur("chemin/vers/image.jpg")
imprimer(résultat)Cela télécharge un modèle de vision pré-entraîné et classe les images en 3 lignes. C’est le pouvoir de Hugging Face.
Exemple 3 : Extraction de données à partir de documents
Utilisez l’IA pour extraire des données structurées à partir de documents :
depuis langchain.llms importer OpenAI
à partir de langchain.prompts, importez PromptTemplate
à partir de langchain.chains importer LLMChain
llm = OpenAI()
template = "Extraire le montant total, la date de la facture et le nom du client de cette facture. Sortie au format JSON : {invoice_text}"
prompt = PromptTemplate(input_variables=["invoice_text"], template=template)
chaîne = LLMChain (llm=llm, invite=invite)
résultat = chain.run(invoice_text=invoice_content)
imprimer(résultat)Cela extrait les données structurées du texte non structuré sans modèles personnalisés.
Optimisation des performances pour les modèles d’IA
Réduction de la taille du modèle : quantification
Les grands modèles sont lents. La quantification convertit les poids des flottants 32 bits en entiers 8 bits, réduisant ainsi la taille de 4 x.
importer la torche
à partir des transformateurs importer AutoModelForSequenceClassification
modèle = AutoModelForSequenceClassification.from_pretrained("bert-base")
quantized = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)Les modèles quantifiés fonctionnent 2 à 4 fois plus rapidement avec une perte de précision minimale.
Traitement par lots pour plus de rapidité
Traitez plusieurs entrées à la fois :
# LENT : Un à la fois
pour le texte dans les textes :
résultat = modèle.predict (texte)
# RAPIDE : Par lots
résultats = model.predict_batch(textes, batch_size=32)Le traitement par lots utilise efficacement le GPU, ce qui accélère les prédictions de 10 à 50 fois.
Mise en cache des réponses LLM
Enregistrer les appels d’API via la mise en cache :
depuis langchain.cache importer InMemoryCache
importer une chaîne de langage
langchain.llm_cache = InMemoryCache()
llm = OpenAI()
result1 = llm("Qu'est-ce que l'IA ?") # Appel API
result2 = llm("Qu'est-ce que l'IA ?") # Utilise le cache, pas d'appel APIPour la production, utilisez Redis pour la mise en cache persistante.
Exécuter des LLM localement
Ollama : Inférence LLM locale
Exécutez des modèles comme Llama 2 localement sans API cloud :
demandes d'importation
importer json
def query_local_llm (invite) :
réponse = requêtes.post("http://localhost:11434/api/generate",
json={"model": "llama2", "prompt": invite, "stream": False})
return réponse.json()["réponse"]
result = query_local_llm("Expliquer l'apprentissage automatique")
imprimer(résultat)Avantages : confidentialité, aucun coût d’API, fonctionne hors ligne.
Inconvénient : plus lent que le cloud, nécessite un GPU.
Guide de sélection de modèle
Commencez petit. Mettez à niveau uniquement si la qualité est insuffisante.
Débogage des modèles d’IA
Utiliser TensorBoard
Visualisez la formation en temps réel :
depuis torch.utils.tensorboard import SummaryWriter
écrivain = RésuméWriter()
pour l'époque dans la plage (100) :
perte = train_one_epoch()
writer.add_scalar("Perte/train", perte, époque)
val_loss = évaluer()
writer.add_scalar("Loss/val", val_loss, époque)
écrivain.close()Vue : tensorboard --logdir=runs
Explicabilité du modèle
Comprenez pourquoi les modèles font des prédictions :
depuis lime.lime_tabular import LimeTabularExplainer
explicateur = LimeTabularExplainer(X_train, mode="classification")
exp = explicateur.explain_instance(X_test[0], model.predict_proba)
exp.show_in_notebook()LIME montre quelles fonctionnalités ont le plus influencé les prédictions.
Profilage de code
Trouver des parties lentes :
importer cProfile
importer des statistiques pstat
profileur = cProfile.Profile()
profileur.enable()
ma_fonction_ai()
profileur.disable()
stats = pstats.Stats (profileur)
stats.sort_stats("cumulative").print_stats(10)Concentrez l’optimisation sur les goulots d’étranglement.
Sécurité et confidentialité
Protéger les données sensibles
N’envoyez jamais de données brutes sensibles aux API. Hachez à la place :
importer hashlib
def anonymize_user_data (nom, email) :
haché = hashlib.sha256(name.encode()).hexdigest()
retourner hachéLimitation de débit
Empêcher l’épuisement des quotas :
à partir des limites d'importation ratelimit, sleep_and_retry
@sleep_and_retry
@limits(appels=100, période=60)
def call_api (invite) :
retourner llm.predict(prompt)Sécurisation des clés API
Ne jamais coder en dur les clés :
importer le système d'exploitation
depuis dotenv importer load_dotenv
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
llm = OpenAI(api_key=api_key)Stocker dans .env (ajouter à .gitignore).
Intégration de production
Requêtes de base de données
importer sqlite3
importer des pandas en tant que PD
conn = sqlite3.connect("base de données.db")
df = pd.read_sql_query("SELECT * FROM clients", conn)
prédictions = model.predict(df)Journalisation
journalisation des importations
logging.basicConfig(niveau=logging.INFO)
enregistreur = journalisation.getLogger(__name__)
essaye :
prédiction = modèle.predict (données)
logger.info(f"Prédiction : {prédiction}")
sauf exception comme e :
logger.error(f"Échec : {e}")Webhooks pour le traitement des événements
depuis l'importation du flacon Flacon, demande
application = Flacon (__nom__)
@app.route("/webhook", méthodes=["POST"])
def handle_webhook() :
données = requête.json
résultat = ai_model.process (données)
return {"status": "traité", "result": résultat}
si __name__ == "__main__":
app.run(port=5000)Les systèmes externes peuvent POST des événements sur votre service d’IA.
Ressources d’apprentissage recommandées
Meilleurs sites Web
- Hugging Face Hub (huggingface.co) : plus d’un million de modèles pré-entraînés
- Tutoriels officiels PyTorch (pytorch.org) : principes fondamentaux du Deep Learning
- Fast.ai (fast.ai) : cours pratiques d’apprentissage profond
- Papers with Code (paperswithcode.com) : recherche + implémentations
Communautés
- r/MachineLearning : communauté Reddit active
- Kaggle : compétitions et ensembles de données
- GitHub : projets open source
- Serveurs Discord : rejoignez les communautés d’IA
Idées de projets pour 2026
- Affinez Llama 2 sur les données de votre domaine
- Créez un chatbot RAG avec Pinecone + LangChain
- Déployer un modèle de vision par ordinateur sur AWS SageMaker
- Créez une API d’analyse des sentiments avec FastAPI
- Créez un moteur de recommandation avec un filtrage collaboratif
Le chemin vers la maîtrise consiste à livrer de vrais projets.
FAQ
Q1 : Combien de temps faut-il pour apprendre Python pour l’IA ?
A : 4 à 8 semaines pour les bases. 3 à 6 mois pour l’apprentissage en profondeur. 1 à 2 ans pour être prêt à travailler (15 à 20 heures/semaine).
Q2 : Ai-je besoin d’un diplôme en mathématiques ?
R : Non. Les compétences pratiques sont les plus importantes. Vous apprendrez les mathématiques sur le tas si nécessaire.
Q3 : Quel est le meilleur premier projet ?
A : Former un modèle sur des données publiques, faire des prédictions, évaluer les résultats. Kaggle est parfait pour cela.
Q4 : PyTorch ou TensorFlow ?
R : PyTorch. Plus facile à apprendre, plus intuitif, domine en 2026.
Créer des systèmes d’IA prêts pour la production
Gérer la dette technique
À mesure que les projets se développent, la dette technique s’accumule. Gérez-le de manière proactive.
Sources courantes :
– Code écrit rapidement sans documentation
– Cas extrêmes mal testés
– Valeurs codées en dur et nombres magiques
– Dépendances obsolètes
Gérer par :
– Écrivez des tests tôt (pas après)
– Documentez au fur et à mesure que vous codez (commentaires, docstrings)
– Refactorisez régulièrement (dédiez 10 à 20 % du temps de sprint)
– Mettre à jour les dépendances mensuellement
– Révisions de code (détection des problèmes avant qu’ils ne se multiplient)
Mise à niveau des services d’IA
Lorsque vous ne disposez plus d’un seul serveur :
docker build -t my-ai:1.0 .
docker pousse mon-ai: 1.0
kubectl apply -f déploiement.yaml # Déployer sur KubernetesKubernetes orchestre les conteneurs et gère automatiquement la mise à l’échelle.
Option avancée : utiliser le mode sans serveur (AWS Lambda, Google Cloud Run). Payez uniquement pour le calcul que vous utilisez.
Surveillance de l’IA en production
Surveillez au-delà des métriques traditionnelles :
importer prometheus_client en tant que bal de promo
model_accuracy = prom.Gauge('model_accuracy', 'Précision actuelle du modèle')
inference_latency = prom.Histogram('inference_ms', 'Latence d'inférence')
prédiction_volume = prom.Counter('predictions_total', 'Total des prédictions')
# Mettre à jour les métriques
model_accuracy.set(0.92)
inference_latency.observer(150)
prédiction_volume.inc()Alerte sur :
– Précision du modèle < seuil
– Latence d’inférence > ligne de base
– Erreurs API > 1%
– Dérive des données (nouvelles données ≠ données d’entraînement)
Construire votre fondation d’IA
La pyramide des compétences essentielles
[Avancé : IA de qualité recherche]
/ [Production ML : Déployer et amp; Moniteur]
/ [Core ML : Modèles et amp; Algorithmes]
/ [Principes fondamentaux et amp; Bibliothèques]
/ [Bases de l'informatique : algorithmes et amp; Structures de données]Vous n’avez pas besoin de maîtriser l’IA de niveau recherche pour créer des systèmes de production. La plupart des travaux nécessitent la couche 2 à 3.
Engagement de temps pour chaque niveau
- Niveau 1 (CS Basics) : 3 à 4 semaines
- Niveau 2 (Python + Bibliothèques) : 4 à 8 semaines
- Niveau 3 (Core ML) : 8 à 16 semaines
- Niveau 4 (Production ML) : 16 à 24 semaines
- Niveau 5 (IA de recherche) : au moins deux ans d’études de niveau doctorat
La plupart des professionnels opèrent aux niveaux 2 à 4.
Conclusion : votre voie à suivre
Vous comprenez désormais Python pour l’IA, l’écosystème, les bibliothèques clés, les exemples pratiques, les tests, le déploiement et les parcours professionnels.
Prochaines étapes :
1. Cette semaine : Configurez l’environnement Python, exécutez un modèle simple
2. La semaine prochaine : Construisez un petit projet (analyse des sentiments, recommandation)
3. Le mois prochain : déployez-le en production (AWS, Heroku ou sans serveur)
4. Ce trimestre : Réalisez un projet de portefeuille, créez une preuve de travail publique
5. Cette année : Contribuez à un rôle ou à un client open source en décrochant le premier rôle d’IA
La barrière à l’entrée est faible. L’avantage est énorme. Commencez dès aujourd’hui.
Q5 : Comment puis-je rester à jour ?
R : Lisez des articles sur arXiv, suivez des chercheurs, construisez des projets, suivez des cours. Consacrez-y 1 à 2 heures par semaine.
Conclusion
Python pour l’IA n’est pas difficile. C’est une compétence qui s’apprend et qui ouvre les portes pour construire l’avenir.
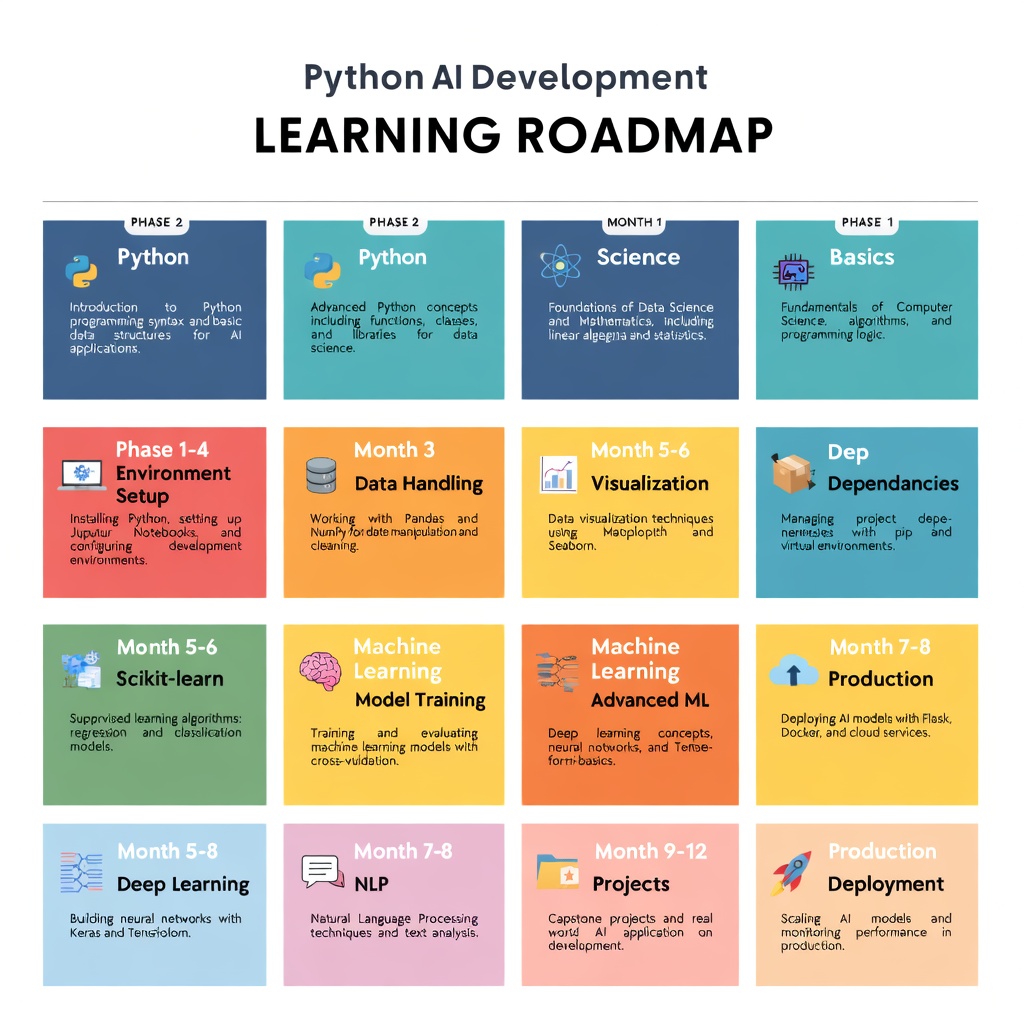
La feuille de route est simple :
Mois 1-2 : Maîtrisez les bases de Python et la configuration de l’environnement. Créez un projet d’exploration de données.
Mois 3-4 : Apprenez NumPy, Pandas, la visualisation. Créez un pipeline de données.
Mois 5-6 : Apprenez scikit-learn. Créez un modèle prédictif.
Mois 7 et 8 : Apprenez PyTorch ou TensorFlow. Reproduire des documents de recherche.
Mois 9 à 12 : Apprenez LangChain. Agents de construction. Déployer en production.
Ce rythme est ambitieux mais réalisable. La clé est la cohérence plutôt que l’intensité. Une heure par jour vaut à chaque fois mieux qu’un cours intensif du week-end.
Commencez aujourd’hui. Choisissez un petit projet : automatisez quelque chose, analysez quelque chose qui vous intéresse, créez quelque chose d’utile. Ensuite, évoluez à partir de là.
Prêt à maîtriser le développement de l’IA ? Rejoignez la communauté learnAI → communauté learnAI Skool