Python per lo sviluppo dell’intelligenza artificiale: guida completa per principianti 2026

⏱ Lettura di 25 minuti · Categoria: Sviluppo IA
Introduzione
Python è il linguaggio dell’intelligenza artificiale. Dai laboratori di ricerca di OpenAI ai sistemi di produzione di Google, Python alimenta la rivoluzione dell’intelligenza artificiale. Se vuoi creare applicazioni AI, Python non è negoziabile.
Ma imparare Python per l’intelligenza artificiale non è come imparare Python per lo sviluppo web. Hai bisogno di librerie, framework e modelli mentali specifici. La maggior parte dei principianti inizia con corsi teorici e si perde in matematica prima di scrivere una singola riga di codice che produca risultati reali.
Questa guida adotta un approccio diverso. Imparerai Python per l’intelligenza artificiale nel modo in cui i professionisti costruiscono effettivamente i sistemi: in modo pratico, focalizzato sul progetto, con teoria appena sufficiente per capire cosa sta succedendo dietro le quinte.
Alla fine, comprenderai l’ecosistema AI di Python, scriverai codice funzionante che utilizza l’apprendimento automatico e le API AI e avrai una tabella di marcia realistica verso la competenza AI.
Statistica chiave: gli sviluppatori che imparano attraverso la creazione impiegano 6-12 mesi per raggiungere la competenza professionale. Coloro che si concentrano prima sui corsi impiegano 18-24 mesi. La differenza? Applicazione immediata.
Sommario
- Perché Python per l’intelligenza artificiale: il vantaggio dell’ecosistema
- Configurazione del tuo ambiente di sviluppo AI Python
- Concetti fondamentali di Python per l’intelligenza artificiale
- Librerie Python essenziali per l’intelligenza artificiale
- Framework di deep learning: PyTorch vs TensorFlow
- Lavorare con modelli pre-addestrati
- Creazione della tua prima applicazione IA
- LangChain: creazione di agenti intelligenti
- Preparazione e preelaborazione dei dati
- Dal prototipo alla produzione
- Insidie comuni e come evitarle
- Domande frequenti
Perché Python per l’intelligenza artificiale: il vantaggio dell’ecosistema
Python non è il linguaggio più veloce. Non è il più elegante. Ma domina l’intelligenza artificiale per una ragione: l’ecosistema.
L’ecosistema
Tutti i principali framework di intelligenza artificiale danno priorità a Python:
- PyTorch: ricerca e produzione di deep learning
- TensorFlow: machine learning scalabile su scala aziendale
- Hugging Face: oltre 1 milione di modelli preaddestrati per testo, visione e audio
- LangChain: creare agenti intelligenti con LLM
- SDK OpenAI Python: API ufficiali per GPT-4, incorporamenti e altro ancora
Quando avviene una nuova svolta nell’intelligenza artificiale, una nuova architettura del modello, una nuova tecnica di formazione, la prima implementazione è sempre in Python.
La Comunità
La comunità AI è innanzitutto Python. Risposte Stack Overflow, progetti GitHub, documenti di ricerca con codice: sono tutti Python. Quando rimani bloccato, l’aiuto è abbondante.
La curva velocità-to-prototipo
Python sacrifica la velocità di esecuzione a favore della velocità di sviluppo. Un’attività che richiede settimane in Java richiede giorni in Python. Per l’intelligenza artificiale, questo compromesso vale la pena. Dedichi il 90% del tuo tempo ad algoritmi e architettura, il 10% all’ottimizzazione delle prestazioni.
Configurazione del tuo ambiente di sviluppo AI Python

Non è necessario hardware costoso per iniziare. Un MacBook o un laptop Windows vanno bene. Se hai una GPU (preferibilmente NVIDIA), ancora meglio, ma non è necessaria per l’apprendimento.
Passaggio 1: installa Python
Scarica Python 3.12 o 3.13, 3.14 da python.org. Evita 3.15+ (troppo nuovo, alcuni pacchetti sono in ritardo).
# Verifica l'installazione
python --versione
# Dovrebbe restituire: Python 3.12.x o 3.14.xPassaggio 2: crea un ambiente virtuale
Non installare mai pacchetti a livello globale. Utilizza sempre ambienti virtuali.
# Crea ambiente
python -m venv myai_env
# Attiva (Mac/Linux)
fonte myai_env/bin/activate
# Attiva (Windows)
myai_env\Scripts\activate
# Il tuo terminale ora dovrebbe mostrare (myai_env)Passaggio 3: installa i pacchetti essenziali
pip installa Numpy Pandas matplotlib scikit-learn jupyterPassaggio 4: installa AI Framework
Per imparare, inizia con PyTorch (più facile per i principianti):
# versione CPU (consigliata per i principianti)
pip installa la torcia torchvision torchaudio
# Versione GPU (se hai GPU NVIDIA)
pip installa torcia torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118Passaggio 5: configura il tuo IDE
Utilizzare:
- VS Code + estensione Python (gratuita, consigliata)
- Community PyCharm (funzionalità gratuite specifiche per l’intelligenza artificiale)
- Cursore (codifica assistita dall’intelligenza artificiale, $ 20/mese)
Passaggio 6: verifica la configurazione
python -c "importa torcia; stampa(torch.__version__)"Dovresti vedere stampato un numero di versione.
In sintesi: la configurazione dell’ambiente richiede 30 minuti. Investi questa volta una volta: risparmierai ore dopo.
Concetti fondamentali di Python per l’intelligenza artificiale

Non è necessario essere un esperto di Python. Devi comprendere questi cinque concetti:
Concetto 1: variabili e tipi
# Numeri
età = 25 # intero
altezza = 5,9 # float
punteggio = 98,5
# Stringhe
nome = "Alice"
messaggio = f"Ciao, {nome}" # stringhe f per la formattazione
# Elenchi (ordinati, modificabili)
numeri = [1, 2, 3, 4, 5]
numeri.append(6)
# Dizionari (coppie chiave-valore)
persona = {"nome": "Alice", "età": 25, "città": "New York"}
print(persona"nome"]) # Accesso: AliceConcetto 2: Funzioni
def saluto(nome):
return f"Ciao, {nome}!"
result = greet("Alice") # Le funzioni accettano input, restituiscono outputConcetto 3: biblioteche e importazioni
# Importa l'intera libreria
importa Numpy come np
# Importa una funzione specifica
da datetime importa datetime
# Usa ciò che hai importato
array = np.array([1, 2, 3, 4, 5])
now = datetime.now()Concetto 4: Elenco di comprensioni (stenografia Pythonic)
# Ciclo tradizionale
al quadrato = []
per il numero in [1, 2, 3, 4, 5]:
quadrato.append(numero ** 2)
# Modo Pythonico
al quadrato = [numero ** 2 per il numero in [1, 2, 3, 4, 5]]
# Entrambi producono: [1, 4, 9, 16, 25]Concetto 5: gestione degli errori
prova:
risultato = 10 / 0 # Fallirà
tranne ZeroDivisionError:
print("Non posso dividere per zero!")
infine:
print("Il codice di pulizia viene eseguito indipendentemente")In sintesi: padroneggia questi cinque concetti e potrai scrivere l’80% del codice AI che incontrerai.
Librerie Python essenziali per l’intelligenza artificiale
NumPy: La Fondazione
NumPy crea array e matrici: la struttura dei dati di tutta l’intelligenza artificiale.
importa numpy come np
# Create arrays
array = np.array([1, 2, 3, 4, 5])
matrice = np.array([[1, 2, 3], [4, 5, 6]])
# Operazioni sugli array
media = np.media(array) # Media
std = np.std(array) # Deviazione standard
normalizzato = (array - media) / std # NormalizzaPanda: manipolazione dei dati
Pandas gestisce il caricamento, la pulizia e l’esplorazione dei dati.
importa panda come pd
# Carica CSV
df = pd.read_csv('dati.csv')
# Esplora
df.head() # Prime 5 righe
df.describe() # Statistiche
df.info() # Tipi di dati e valori mancanti
# Pulito
df = df.dropna() # Rimuove i valori mancanti
df['age'] = df['age'].astype(int) # Converte i tipi
#Filtra
giovani_persone = df[df['età'] < 30]Matplotlib e Seaborn: visualizzazione
Non puoi eseguire il debug di ciò che non puoi vedere.
importa matplotlib.pyplot come plt
importare seaborn come sns
# Trama a linee
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
plt.xlabel('X')
plt.yetichetta('Y')
plt.mostra()
# Istogramma
sns.histplot(data=df, x='età', bin=20)
plt.show()Scikit-Learn: ML classico
Per le attività che non richiedono il deep learning, scikit-learn è il più veloce.
da sklearn.linear_model importa LinearRegression
da sklearn.model_selection import train_test_split
# Dividi i dati
X_treno, X_test, y_treno, y_test = treno_test_split(
funzionalità, etichette, test_size=0.2
)
# Modello di treno
modello = RegressioneLineare()
modello.fit(treno_X, treno_y)
# Valuta
punteggio = model.score(X_test, y_test)Framework di deep learning: PyTorch vs TensorFlow
Entrambi sono eccellenti. PyTorch è più amichevole per i principianti. TensorFlow è migliore per la scala di produzione.
PyTorch: la scelta della ricerca
Il codice PyTorch si legge come un normale Python. Gli errori sono chiari. La curva di apprendimento è delicata.
importa torcia
importa torch.nn come nn
# Crea una semplice rete neurale
classe SimpleNet(nn.Modulo):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 128) # 784 input → 128 neuroni
self.fc2 = nn.Linear(128, 10) # 128 neuroni → 10 uscite
def avanti(self, x):
x = torcia.relu(self.fc1(x))
x = self.fc2(x)
restituire x
# Istanziare
modello = SimpleNet()
# Passaggio in avanti
input_data = torch.randn(32, 784) # 32 campioni, 784 funzionalità
output = modello(input_data)TensorFlow: la scelta della produzione
TensorFlow si adatta a set di dati e GPU di grandi dimensioni. Più cerimonia, ma più controllo.
importa tensorflow come tf
# Crea modello
modello = tf.keras.Sequential([
tf.keras.layers.Dense(128, attivazione='relu', input_shape=(784,)),
tf.keras.layers.Dense(10, attivazione='softmax')
])
# Compila
modello.compile(
ottimizzatore='Adamo',
perdita='sparse_categorical_crossentropy',
metriche=['precisione']
)
# Treno
model.fit(X_train, y_train, epochs=10)In sintesi: inizia con PyTorch per imparare. Passa a TensorFlow se hai bisogno di implementare su scala aziendale.
Utilizzo di modelli preaddestrati
L’addestramento dei modelli da zero è lento e costoso. I modelli pre-addestrati sono molto più veloci.
Trasformatori di volti abbracciati
Hugging Face ospita oltre 1 milione di modelli open source.
dalla pipeline di importazione dei trasformatori
# Generazione del testo
generatore = pipeline('generazione testo', modello='gpt2')
risultato = generatore('C'era una volta', max_length=50)
stampa(risultato)
# Analisi del sentiment
classificatore = pipeline('analisi-sentiment')
risultato = classificatore("Adoro questo film!")
# Risultato: [{'label': 'POSITIVE', 'score': 0,9999}]
# Riconoscimento dell'entità denominata
ner = pipeline('ner')
risultato = ner("Apple Inc ha sede a Cupertino, California")
# Estrae organizzazioni, luoghi, personeAPI OpenAI (GPT-4, incorporamenti)
I modelli più potenti sono accessibili tramite API.
da openai importa OpenAI
client = OpenAI(api_key="tua-chiave-api")
# Genera testo
risposta = client.chat.completions.create(
modello="gpt-4",
messaggi=[
{"role": "user", "content": "Spiega il calcolo quantistico in 2 frasi"}
]
)
print(response.choices[0].message.content)Perfezionamento dei modelli pre-addestrati
Adatta i modelli al tuo dominio specifico.
dai trasformatori importa Trainer, TrainingArguments
training_args = ArgomentiFormazione(
output_dir='./risultati',
num_treno_epoche=3,
per_device_train_batch_size=16,
)
allenatore = allenatore(
modello=modello,
args=formazione_args,
treno_dataset=treno_dataset,
)
trainer.train()Crea la tua prima applicazione AI
Costruiamo un analizzatore del sentiment che classifichi le recensioni dei film.
Passaggio 1: ottieni dati
importa panda come pd
# Carica i dati del campione
dati = {
'recensione': [
'Questo film è fantastico!',
'Terribile perdita di tempo',
"Non male, vale la pena guardarlo"
],
'sentimento': ['positivo', 'negativo', 'positivo']
}
df = pd.DataFrame(dati)Passaggio 2: caricamento del modello pre-addestrato
dalla pipeline di importazione dei trasformatori
classificatore = pipeline('analisi-sentiment')Passaggio 3: fai previsioni
recensioni = df['review'].tolist()
previsioni = classificatore(recensioni)
# Aggiungi al dataframe
df['predicted_sentiment'] = [
pred['label'].lower() per pred nelle previsioni
]
print(df)Passaggio 4: valutazione
# Confronta il previsto con l'effettivo
precisione = (df['sentiment'] == df['predicted_sentiment']).mean()
print(f"Precisione: {precisione:.2%}")Conclusioni principali: l’intero flusso di lavoro (caricare dati, fare previsioni, valutare) ha richiesto 20 righe di codice. Questo è il potere dei modelli preaddestrati.
LangChain: creazione di agenti intelligenti
LangChain collega i LLM a strumenti esterni. Ciò consente agli agenti di effettuare ricerche sul Web, leggere PDF ed eseguire codice.
Catena LLM di base
from langchain.chat_models import ChatOpenAI
da langchain.prompts importa ChatPromptTemplate
llm = ChatOpenAI(modello="gpt-4", temperatura=0)
# Crea richiesta
prompt = ChatPromptTemplate.from_messages([
("utente", "Spiega {argomento} in 2 frasi")
])
# Crea catena
catena = prompt | llm
# Esegui
risultato = chain.invoke({"topic": "machine learning"})
print(risultato.contenuto)Agente con strumenti
da langchain.agents importa inizializza_agent, strumento
dallo strumento di importazione langchain.tools
da langchain.chat_models importa ChatOpenAI
@strumento
def calcolatrice(espressione: str) -> stringa:
"""Valuta le espressioni matematiche"""
return str(eval(espressione))
@strumento
def ricerca_web(query: str) -> stringa:
"""Cerca nel Web"""
# Implementa con la libreria delle richieste
return f"Risultati per {query}"
strumenti = [calcolatrice, ricerca_web]
llm = ChatOpenAI(modello="gpt-4")
agente = inizializza_agente(tools, llm, agent="zero-shot-react-description")
result = agent.run("Quanto fa 2+2? Allora cerca la capitale della Francia")Questo agente sceglie quali strumenti utilizzare e in quale ordine, in modo del tutto autonomo.
Preparazione e preelaborazione dei dati
La maggior parte dei progetti di intelligenza artificiale dedica il 70% del tempo alla preparazione dei dati. Impara presto questa abilità.
Caricamento dati
importa panda come pd
#CSV
df = pd.read_csv('dati.csv')
#JSON
df = pd.read_json('data.json')
#Database SQL
importa sqlite3
conn = sqlite3.connect('database.db')
df = pd.read_sql('SELECT * FROM tabella', conn)Pulizia dei dati
# Rimuove i valori mancanti
df = df.dropna()
# Riempi i valori mancanti
df['età'].fillna(df['età'].mean(), inplace=True)
# Rimuovi i duplicati
df = df.drop_duplicates()
# Rimuovi i valori anomali (valori oltre 3 sviluppatori standard)
df = df[
(df['età'] > df['età'].mean() - 3 * df['età'].std()) &
(df['età'] < df['età'].mean() + 3 * df['età'].std())
]Ingegneria delle funzionalità
# Crea nuove funzionalità
df['age_squared'] = df['age'] ** 2
df['age_category'] = pd.cut(df['age'], bins=[0, 18, 65, 100])
# Codifica variabili categoriali
df = pd.get_dummies(df, columns=['città'])
# Scala le caratteristiche numeriche
da sklearn.preprocessing importa StandardScaler
scalatore = StandardScaler()
df[['età', 'reddito']] = scaler.fit_transform(df[['età', 'reddito']])Dal prototipo alla produzione
Il passaggio dai notebook Jupyter alla produzione richiede struttura.
Struttura del progetto
mio_progetto_ai/
├── dati/
│ ├── crudo/
│ └── elaborato/
├── modelli/
│ └──trained_model.pkl
├── quaderni/
│ └── esplorazione.ipynb
├── fonte/
│ ├── __init__.py
│ ├── data_loader.py
│ ├── modello.py
│ └── predit.py
├── requisiti.txt
└── README.mdEsempio di script di produzione
# src/predict.py
importare sottaceti
importa i panda come pd
classe ModelPipeline:
def __init__(self, percorso_modello):
con open(model_path, 'rb') come f:
self.modello = pickle.load(f)
def predire(self, input_data):
"""input_data: panda DataFrame"""
previsioni = self.model.predict(input_data)
previsioni di ritorno
if __nome__ == '__principale__':
pipeline = ModelPipeline('models/trained_model.pkl')
test_data = pd.read_csv('dati/elaborati/test.csv')
previsioni = pipeline.predict(test_data)
print(previsioni)Distribuzione con FastAPI
da fastapi importa FastAPI
dall'importazione pydantic BaseModel
importare sottaceti
app = API veloce()
# Carica il modello una volta all'avvio
con open('models/trained_model.pkl', 'rb') come f:
modello = pickle.load(f)
classe PredictionRequest(BaseModel):
età: int
reddito: fluttuante
@app.post("/predict")
def predire(richiesta: PredictionRequest):
previsione = model.predict([[request.age, request.income]])
return {"previsione": float(previsione[0])}
# Esegui: uvicorn app:app --reloadInsidie comuni e come evitarle
Trappola 1: passare direttamente al deep learning
Il deep learning è potente ma eccessivo per la maggior parte dei problemi. Prova prima scikit-learn.
Correzione: la regressione lineare, le foreste casuali e l'incremento del gradiente risolvono l'80% dei problemi senza il deep learning.
Trappola 2: lavorare senza controllo della versione
Itererai costantemente. Tieni traccia del tuo lavoro.
Correzione: utilizza Git fin dal primo giorno. Invia a GitHub.
git init
git aggiungi .
git commit -m "Commit iniziale"
git push origin mainTrappola 3: non documentare il codice
Dimenticherai ciò che hai scritto tra 2 settimane.
Correzione: aggiungi stringhe di documento alle funzioni:
def predit_sentiment(testo):
"""
Classificare il sentiment del testo come positivo o negativo.
Argomenti:
text (str): il testo da classificare
Resi:
str: 'positivo' o 'negativo'
"""
# Implementazione
restituisce il risultatoTrappola 4: formazione su tutti i tuoi dati
Non puoi valutare i dati su cui hai effettuato la formazione. Prenota sempre i dati dei test.
Correzione: dividi i tuoi dati:
da sklearn.model_selection import train_test_split
X_treno, X_test, y_treno, y_test = treno_test_split(
X, y, dimensione_test=0,2, stato_casuale=42
)Trappola 5: ignorare lo squilibrio dei dati
Se si prevede una frode (0,1% dei casi), un modello che prevede "non frode" è sempre accurato al 99,9% ma inutile.
Correzione: utilizza metriche appropriate (punteggio F1, AUC-ROC) e tecniche di ricampionamento.
FAQ
D: Quanto tempo ci vuole per imparare Python per l'intelligenza artificiale?
6-12 mesi di pratica costante per raggiungere la competenza professionale. Più veloce se crei progetti immediatamente. Più lento se guardi i corsi senza codificare.
D: Ho bisogno di una GPU?
No, non per iniziare. Una moderna CPU per laptop va bene per l'apprendimento. La GPU accelera l'addestramento per modelli di grandi dimensioni (utile una volta comprese le nozioni di base).
D: Dovrei prima imparare la matematica o prima la programmazione?
Prima di tutto la codifica. Impara la matematica man mano che la incontri. La teoria senza pratica viene dimenticata rapidamente.
D: Qual è l'ordine migliore per apprendere le biblioteche?
NumPy → Panda → Matplotlib → Scikit-Learn → PyTorch (o TensorFlow) → LangChain.
D: Come faccio a sapere se sono pronto per la produzione?
Sei pronto quando puoi:
1. Carica e pulisci i dati in modo indipendente
2. Addestra un modello senza copiare e incollare il codice
3. Valuta le prestazioni con metriche appropriate
4. Distribuisci a una semplice API
D: dovrei utilizzare Jupyter o VS Code?
Entrambi. Jupyter per l'esplorazione e l'apprendimento. VS Code per progetti destinati alla produzione.
D: Come posso rimanere aggiornato con l'IA in rapida evoluzione?
Segui: Papers with Code, Hugging Face Blog, forum fast.ai. Realizza progetti utilizzando nuovi strumenti: questo è l'apprendimento più rapido.
Librerie Python avanzate per lo sviluppo di intelligenza artificiale
PyTorch per il deep learning
PyTorch è il framework preferito per l'intelligenza artificiale di ricerca e produzione. È pitonato, flessibile e ampiamente adottato dai principali team di intelligenza artificiale di Meta, Tesla e OpenAI.
importa torcia
importa torch.nn come nn
da torch.utils.data importa DataLoader, TensorDataset
classe SimpleNet(nn.Modulo):
def __init__(self, dimensione_input, dimensione_nascosta, dimensione_output):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(dimensione_input, dimensione_nascosta)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(dimensione_nascosta, dimensione_output)
def avanti(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
restituire x
modello = SimpleNet(10, 64, 2)
perdita_fn = nn.CrossEntropyLoss()
ottimizzatore = torch.optim.Adam(model.parameters(), lr=0.001)
per l'epoca nell'intervallo (100):
uscite = modello(X_treno)
perdita = perdita_fn(uscite, y_treno)
ottimizzatore.zero_grad()
perdita.indietro()
ottimizzatore.step()Punto chiave: PyTorch consente una sperimentazione rapida. Cambia architetture e funzioni di perdita con solo poche righe di codice.
LangChain per applicazioni LLM
LangChain semplifica la creazione di applicazioni su modelli linguistici come GPT-4. Gestisce prompt, catene, memoria e integrazioni.
dall'importazione langchain OpenAI, LLMChain, PromptTemplate
llm = OpenAI(api_key="sk-...", temperatura=0.7)
template = "Sei un utile assistente AI. Domanda dell'utente: {question}. Risposta utile:"
prompt = PromptTemplate(input_variables=["domanda"], template=template)
catena = LLMChain(llm=llm, prompt=prompt)
risultato = chain.run("Cos'è l'apprendimento automatico?")
print(risultato)Utilizza LangChain per: chatbot, risposte a domande, riepiloghi, catene di ragionamento in più fasi.
Database vettoriali: Pinecone e Weaviate
Per le applicazioni AI che utilizzano incorporamenti, i database vettoriali archiviano ed eseguono query sugli incorporamenti in modo efficiente.
importa pigna
pigna.init(api_key="...", ambiente="us-west1-gcp")
indice = pigna.Indice("documenti")
incorporamenti = [[0.1, 0.2, 0.3], [0.4, 0.5, 0.6]]
ID = ["doc1", "doc2"]
index.upsert(vettori=list(zip(id, incorporamenti)))
query_embedding = [0,15, 0,25, 0,35]
risultati = index.query(query_embedding, top_k=5)I database vettoriali potenziano i sistemi di raccomandazione, la ricerca semantica e la generazione aumentata di recupero.
Deploying di modelli AI in produzione
Containerizzazione con Docker
Docker impacchetta il codice e le dipendenze in un contenitore coerente.
DA python:3.11-slim
DIR LAVORO /app
COPIA requisiti.txt .
ESEGUI pip install -r requisiti.txt
COPIA. .
CMD ["python", "app.py"]Costruisci ed esegui:
docker build -t my-ai-app:1.0 .
docker run -p 8000:8000 my-ai-app:1.0Docker garantisce che il tuo modello funzioni in modo identico in fase di sviluppo, test e produzione.
Distribuzione API con FastAPI
FastAPI è veloce e moderna per servire modelli di intelligenza artificiale.
da fastapi importa FastAPI
dall'importazione pydantic BaseModel
importa la libreria di lavoro
app = API veloce()
modello = joblib.load("modello.pkl")
classe PredictionRequest(BaseModel):
caratteristiche: elenco
@app.post("/predict")
def predire(richiesta: PredictionRequest):
previsione = model.predict([request.features])[0]
return {"prediction": previsione}Avvia il server:
pip installa fastapi uvicorn
app uvicorn:app --host 0.0.0.0 --port 8000Ora qualsiasi applicazione può chiamare il tuo modello: POST http://localhost:8000/predict
Piattaforme di distribuzione (2026)
Hugging Face Spaces: gratuito per i modelli open source. Facile da condividere e provare.
AWS SageMaker: di livello aziendale con scalabilità, monitoraggio e controllo delle versioni.
Render o Railway: implementazione semplice ed economica. Inizia da $ 7 al mese.
Google Cloud Run: pagamento per richiesta, senza server. Ideale per carichi di lavoro variabili.
Vercel: il migliore per frontend e intelligenza artificiale. Spedisci app complete in pochi minuti.
Testare il codice AI
Modelli di unit test
Verifica le previsioni del tuo modello con input noti.
importa unittest
importa Numpy come np
classe TestModel(unittest.TestCase):
def impostazione(self):
self.model = load_model("percorso/del/modello")
def test_prediction_shape(self):
X = np.array([[1, 2, 3], [4, 5, 6]])
y = self.model.predict(X)
self.assertEqual(y.forma, (2, 1))
def intervallo_previsione_test(self):
X = np.array([[1, 2, 3]])
y = self.model.predict(X)[0]
self.assertTrue(0 <= y <= 1)
if __nome__ == '__principale__':
unittest.main()Monitoraggio delle prestazioni del modello
Monitora l'accuratezza del modello, la latenza e la deriva dei dati nella produzione.
da sklearn.metrics importa accurato_score
importare la registrazione
logger = logging.getLogger(__name__)
def monitor_predictions(true_labels, previsioni):
precisione = punteggio_accuratezza(true_labels, previsioni)
logger.info(f"Precisione del modello: {precisione:.4f}")
se precisione < 0,85:
logger.warning("Precisione del modello inferiore alla soglia!")
precisione del resoErrori comuni di sviluppo dell'IA
Errore 1: perdita di dati
Problema: i dati del test includono accidentalmente informazioni provenienti dai dati di addestramento.
# SBAGLIATO
X_normalizzato = normalizza(X)
X_treno, X_test = treno_test_split(X_normalizzato)
# CORRETTO
X_treno, X_test, y_treno, y_test = treno_test_split(X, y)
X_treno = normalizza(X_treno)
X_test = normalizza(X_test)Errore 2: adattamento eccessivo a set di dati di piccole dimensioni
Utilizza la regolarizzazione e la convalida incrociata.
da sklearn.model_selection importa cross_val_score
da sklearn.linear_model importa LogisticRegression
punteggi = cross_val_score(LogisticRegression(C=1.0), X, y, cv=5)
print(f"Precisione CV: {scores.mean():.4f} (+/- {scores.std():.4f})")Errore 3: utilizzo della metrica sbagliata
Per set di dati sbilanciati, utilizza F1 o accuratezza bilanciata anziché accuratezza.
da sklearn.metrics importa f1_score, Balanced_accuracy_score
f1 = punteggio_f1(y_vero, y_pred)
Balanced_acc = Balanced_accuracy_score(y_true, y_pred)Errore 4: non gestire i dati mancanti
da sklearn.impute importa SimpleImputer
imputer = SimpleImputer(strategia="media")
X_imputato = imputer.fit_transform(X)Idee di progetti AI per l'apprendimento
Progetto 1: Chatbot per l'analisi del sentiment (principiante - 2 settimane)
Costruisci un chatbot che classifica il sentiment e risponde.
Strumenti: Transformers, FastAPI, Gradio
Steps: (1) Use Hugging Face sentiment model (2) Build FastAPI endpoint (3) Create Gradio UI (4) Deploy on Hugging Face Spaces
Competenze: API del modello, implementazione, integrazione dell'interfaccia utente
Progetto 2: Recommendation Engine (intermedio – 4 settimane)
Crea un consiglio di film utilizzando il filtro collaborativo.
Strumenti: LightFM, Pandas, PostgreSQL
Passaggi: (1) Ottieni set di dati di suggerimenti (2) Crea un modello di filtro collaborativo (3) Crea API (4) Distribuisci su AWS/Render
Competenze: sistemi di raccomandazione, query di database, progettazione API
Progetto 3: sistema di domande e risposte sui documenti (avanzato – 6 settimane)
Costruisci un sistema che risponda alle domande sui tuoi documenti utilizzando RAG.
Strumenti: LangChain, OpenAI, Pinecone, FastAPI
Passaggi: (1) Caricare e dividere in blocchi i documenti (2) Generare incorporamenti, archiviarli in Pinecone (3) Recuperare blocchi per le domande degli utenti, chiamare LLM (4) Distribuire come app Web
Competenze: LLM, incorporamenti, ricerca vettoriale, distribuzione in produzione
Percorso di carriera: da principiante a ingegnere AI
Mesi 1–3: Fondazioni
Focus: nozioni di base su Python, fondamenti di ML, primi modelli
Azione: corso Python (2–3 settimane) → NumPy, Pandas (2 settimane) → progetto scikit-learn (2 settimane)
Risultato: creare semplici modelli di classificazione/regressione
Prospettive di lavoro: ingegnere junior di ML, analista di dati ($ 60-80.000)
Mesi 4–6: Deep Learning
Focus: reti neurali, PyTorch, modelli di immagini/PNL
Azione: Teoria delle reti neurali (2 settimane) → PyTorch CNN (3 settimane) → NLP Transformers (2 settimane)
Risultato: formare e implementare modelli di deep learning
Prospettive di lavoro: ingegnere ML, ingegnere AI ($ 120-160.000)
Mesi 7–12: produzione e amp; Specializzazione
Focus: distribuzione, LLM, scalabilità, specializzazione
Azione: scegli la specializzazione (CV/PNL/raccomandazioni) → crea 2-3 progetti di portfolio → distribuisci in produzione → contribuisci all'open source
Risultato: spedire i prodotti IA alla produzione
Prospettive di lavoro: ingegnere senior di ML, ingegnere di prodotto AI ($ 150-250.00+)
Oltre l'anno 1: padronanza e amp; Leadership
Opzioni:
– Ricercatore: focus dottorato, laboratori FAANG ($ 180–300.000+)
– Fondatore di startup: crea un prodotto AI (da 0 a 10 milioni di dollari +, ad alto rischio)
– Architetto AI: guida le strategie aziendali di AI ($ 200-400.000)
– Scienziato dell'intelligenza artificiale: modelli di frontiera (oltre 200-500.000 $)
Chiave: Costruisci progetti reali, spedisci alla produzione, comprendi l'impatto sul business.
Applicazioni AI: esempi Python del mondo reale
Esempio 1: creazione di un semplice chatbot con LangChain
Ecco un chatbot completo che ricorda il contesto della conversazione:
da langchain.llms importa OpenAI
da langchain.memory importa ConversationBufferMemory
da langchain.chains importa ConversationChain
memoria = ConversationBufferMemory()
llm = OpenAI(api_key="sk-...")
conversazione = ConversationChain(llm=llm, memoria=memoria)
mentre Vero:
input_utente = input("Tu: ")
risposta = conversazione.run(input=user_input)
print(f"Bot: {risposta}")Questo chatbot conserva automaticamente la cronologia delle conversazioni. ConversationBufferMemory memorizza l'intera conversazione, quindi il modello ha un contesto per le domande successive.
Esempio 2: classificazione delle immagini con Hugging Face
Classificare le immagini senza addestrare un modello:
dalla pipeline di importazione dei trasformatori
classificatore = pipeline("classificazione immagine",
modello="google/vit-base-patch16-224")
risultato = classificatore("percorso/dell'immagine.jpg")
print(risultato)Questo scarica un modello di visione pre-addestrato e classifica le immagini in 3 righe. Questo è il potere di Hugging Face.
Esempio 3: estrazione di dati da documenti
Utilizza l'intelligenza artificiale per estrarre dati strutturati dai documenti:
da langchain.llms importa OpenAI
da langchain.prompts importa PromptTemplate
da langchain.chains importa LLMChain
llm = OpenAI()
template = "Estrai l'importo totale, la data della fattura, il nome del cliente da questa fattura. Output come JSON: {invoice_text}"
prompt = PromptTemplate(input_variables=["invoice_text"], template=template)
catena = LLMChain(llm=llm, prompt=prompt)
risultato = chain.run(invoice_text=invoice_content)
print(risultato)Questo estrae i dati strutturati dal testo non strutturato senza modelli personalizzati.
Ottimizzazione delle prestazioni per i modelli AI
Riduzione delle dimensioni del modello: quantizzazione
I modelli di grandi dimensioni sono lenti. La quantizzazione converte i pesi da numeri in virgola mobile a 32 bit a numeri interi a 8 bit, riducendo le dimensioni di 4 volte.
importa torcia
dai trasformatori importa AutoModelForSequenceClassification
modello = AutoModelForSequenceClassification.from_pretrained("bert-base")
quantizzato = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)I modelli quantizzati vengono eseguiti da 2 a 4 volte più velocemente con una perdita di precisione minima.
Elaborazione batch per velocità
Elabora più input contemporaneamente:
# LENTO: uno alla volta
per il testo nei testi:
risultato = modello.predict(testo)
# VELOCE: in lotti
risultati = model.predict_batch(texts, batch_size=32)Il batch utilizza la GPU in modo efficiente, accelerando le previsioni di 10-50 volte.
Memorizzazione nella cache delle risposte LLM
Salva le chiamate API memorizzando nella cache:
da langchain.cache importa InMemoryCache
importare langchain
langchain.llm_cache = InMemoryCache()
llm = OpenAI()
risultato1 = llm("Cos'è l'AI?") # Chiamata API
risultato2 = llm("Cos'è l'AI?") # Utilizza la cache, nessuna chiamata APIPer la produzione, utilizza Redis per la memorizzazione nella cache persistente.
Esecuzione di LLM localmente
Ollama: inferenza LLM locale
Esegui modelli come Llama 2 localmente senza API cloud:
richieste di importazione
importa json
def query_local_llm(prompt):
risposta = request.post("http://localhost:11434/api/generate",
json={"model": "llama2", "prompt": prompt, "stream": False})
restituire risposta.json()["risposta"]
risultato = query_local_llm("Spiega il machine learning")
print(risultato)Vantaggi: privacy, nessun costo API, funziona offline.
Svantaggio: più lento del cloud, necessita di GPU.
Guida alla selezione del modello
Inizia in piccolo. Aggiorna solo se la qualità è insufficiente.
Debug dei modelli AI
Utilizzo di TensorBoard
Visualizza la formazione in tempo reale:
da torch.utils.tensorboard importa SummaryWriter
scrittore = RiepilogoWriter()
per l'epoca nell'intervallo (100):
perdita = treno_una_epoca()
writer.add_scalar("Perdita/treno", perdita, epoca)
val_perdita = valutare()
writer.add_scalar("Perdita/val", val_loss, epoca)
writer.close()Visualizza: tensorboard --logdir=runs
Spiegabilità del modello
Comprendi perché i modelli fanno previsioni:
da lime.lime_tabular importa LimeTabularExplainer
spiegatore = LimeTabularExplainer(X_train, mode="classificazione")
exp = spiegatore.explain_instance(X_test[0], model.predict_proba)
exp.show_in_notebook()LIME mostra quali funzionalità hanno influenzato maggiormente le previsioni.
Profilazione del codice
Trova parti lente:
importa cProfile
importare pstat
profiler = cProfile.Profile()
profiler.abilita()
mia_ai_funzione()
profiler.disable()
stats = pstats.Stats(profilatore)
stats.sort_stats("cumulativo").print_stats(10)Ottimizzazione focalizzata sui colli di bottiglia.
Sicurezza e privacy
Protezione dei dati sensibili
Non inviare mai dati sensibili grezzi alle API. Hash invece:
importa hashlib
def anonymize_user_data(nome, email):
hash = hashlib.sha256(nome.encode()).hexdigest()
restituisce l'hashLimitazione della velocità
Previeni l'esaurimento della quota:
dai limiti di importazione ratelimit, sleep_and_retry
@sleep_and_retry
@limits(chiamate=100, periodo=60)
def chiamata_api(prompt):
restituisce llm.predict(prompt)Protezione delle chiavi API
Non codificare mai le chiavi:
importa sistema operativo
da dotenv import load_dotenv
caricamento_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
llm = OpenAI(api_key=api_key)Memorizza in .env (aggiungi a .gitignore).
Integrazione della produzione
Query sul database
importa sqlite3
importa i panda come pd
conn = sqlite3.connect("database.db")
df = pd.read_sql_query("SELECT * FROM clienti", conn)
previsioni = model.predict(df)Registrazione
importa la registrazione
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
prova:
previsione = modello.previsione(dati)
logger.info(f"Previsione: {previsione}")
tranne Eccezione come e:
logger.error(f"Non riuscito: {e}")Webhook per l'elaborazione degli eventi
dall'importazione di flask Flask, richiesta
app = Pallone(__nome__)
@app.route("/webhook", metodi=["POST"])
def handle_webhook():
dati = richiesta.json
risultato = ai_model.process(dati)
return {"status": "elaborato", "risultato": risultato}
if __name__ == "__main__":
app.run(port=5000)I sistemi esterni possono POSTARE eventi al tuo servizio AI.
Risorse didattiche consigliate
Siti web migliori
- Hugging Face Hub (huggingface.co): oltre 1 milione di modelli pre-addestrati
- Tutorial ufficiali PyTorch (pytorch.org): nozioni di base sul deep learning
- Fast.ai (fast.ai): corsi pratici di deep learning
- Papers with Code (paperswithcode.com): ricerca e implementazioni
Comunità
- r/MachineLearning: comunità Reddit attiva
- Kaggle: competizioni e set di dati
- GitHub: progetti open source
- Server Discord: unisciti alle comunità AI
Idee progettuali per il 2026
- Perfeziona Llama 2 sui dati del tuo dominio
- Build a RAG chatbot with Pinecone + LangChain
- Distribuisci un modello di visione artificiale ad AWS SageMaker
- Crea un'API di analisi del sentiment con FastAPI
- Crea un motore di suggerimenti con filtri collaborativi
Il percorso verso la maestria è realizzare progetti reali.
FAQ
D1: Quanto tempo ci vuole per imparare Python per l'intelligenza artificiale?
R: 4-8 settimane per le nozioni di base. 3–6 mesi per il deep learning. 1–2 anni per essere pronto al lavoro (15–20 ore/settimana).
Q2: Ho bisogno di una laurea in matematica?
R: No. Le competenze pratiche contano di più. Se necessario, imparerai la matematica sul lavoro.
Q3: Qual è il miglior primo progetto?
R: Addestra un modello su dati pubblici, fai previsioni, valuta i risultati. Kaggle è perfetto per questo.
Q4: PyTorch o TensorFlow?
R: PyTorch. Più facile da imparare, più intuitivo, domina nel 2026.
Creazione di sistemi IA pronti per la produzione
Gestione del debito tecnico
Man mano che i progetti crescono, il debito tecnico si accumula. Gestiscilo in modo proattivo.
Fonti comuni:
– Codice scritto rapidamente senza documentazione
– Custodie marginali scarsamente testate
– Valori codificati e numeri magici
– Dipendenze obsolete
Gestisci entro:
– Scrivi i test in anticipo (non dopo)
– Documenta mentre codifichi (commenti, docstring)
– Effettua il refactoring regolarmente (dedica il 10–20% del tempo dello sprint)
– Aggiorna le dipendenze mensilmente
– Revisioni del codice (rilevare i problemi prima che si moltiplichino)
Ridimensionamento dei servizi AI
Quando diventi troppo grande per un singolo server:
docker build -t my-ai:1.0 .
docker push my-ai:1.0
kubectl apply -f deploy.yaml # Distribuisci a KubernetesKubernetes orchestra i contenitori e gestisce il ridimensionamento automaticamente.
Opzione avanzata: utilizza serverless (AWS Lambda, Google Cloud Run). Paga solo per il calcolo che utilizzi.
Monitoraggio dell'IA in produzione
Monitoraggio oltre le metriche tradizionali:
importa prometheus_client come ballo di fine anno
model_accuracy = prom.Gauge('model_accuracy', 'Precisione del modello attuale')
inference_latency = prom.Histogram('inference_ms', 'Latenza inferenza')
previsione_volume = prom.Counter('previsioni_totale', 'Previsioni totali')
# Aggiorna le metriche
model_accuracy.set(0.92)
inference_latency.observe(150)
predizione_volume.inc()Alert on:
– Precisione del modello < soglia
– Latenza di inferenza > riferimento
– Errori API > 1%
– Deriva dei dati (nuovi dati ≠ dati di addestramento)
Costruisci le tue basi per l'AI
La piramide delle competenze essenziali
[Avanzato: IA di livello ricerca]
/ [ML di produzione: distribuzione e amp; Monitorare]
/ [Core ML: modelli e amp; Algoritmi]
/ [Nozioni fondamentali di Python e amp; Biblioteche]
/ [Nozioni di base di informatica: algoritmi - Strutture dati]Non è necessario padroneggiare l'intelligenza artificiale a livello di ricerca per creare sistemi di produzione. La maggior parte dei lavori richiede il livello 2-3.
Impegno di tempo per ogni livello
- Livello 1 (Nozioni di base su CS): 3-4 settimane
- Livello 2 (Python + Biblioteche): 4–8 settimane
- Livello 3 (Core ML): 8-16 settimane
- Livello 4 (Produzione ML): 16-24 settimane
- Livello 5 (Ricerca AI): studio di livello dottorato di ricerca di oltre 2 anni
La maggior parte dei professionisti opera ai livelli 2–4.
Conclusione: il tuo percorso da seguire
Ora comprendi Python per l'intelligenza artificiale, l'ecosistema, le librerie chiave, gli esempi pratici, i test, l'implementazione e i percorsi di carriera.
Passaggi successivi:
1. Questa settimana: configura l'ambiente Python, esegui un modello semplice
2. La prossima settimana: crea un piccolo progetto (analisi del sentiment, consigli)
3. Il mese prossimo: distribuiscilo in produzione (AWS, Heroku o serverless)
4. Questo trimestre: completa un progetto di portfolio, crea prove di lavoro pubbliche
5. Quest'anno: contribuisci all'open source, ottieni il primo ruolo o cliente IA
La barriera all'ingresso è bassa. Il vantaggio è enorme. Inizia oggi.
Q5: Come faccio a rimanere aggiornato?
R: Leggi articoli su arXiv, segui ricercatori, crea progetti, segui corsi. Dedica 1–2 ore a settimana.
Conclusione
Python per l'intelligenza artificiale non è difficile. È un'abilità apprendibile che apre le porte alla costruzione del futuro.
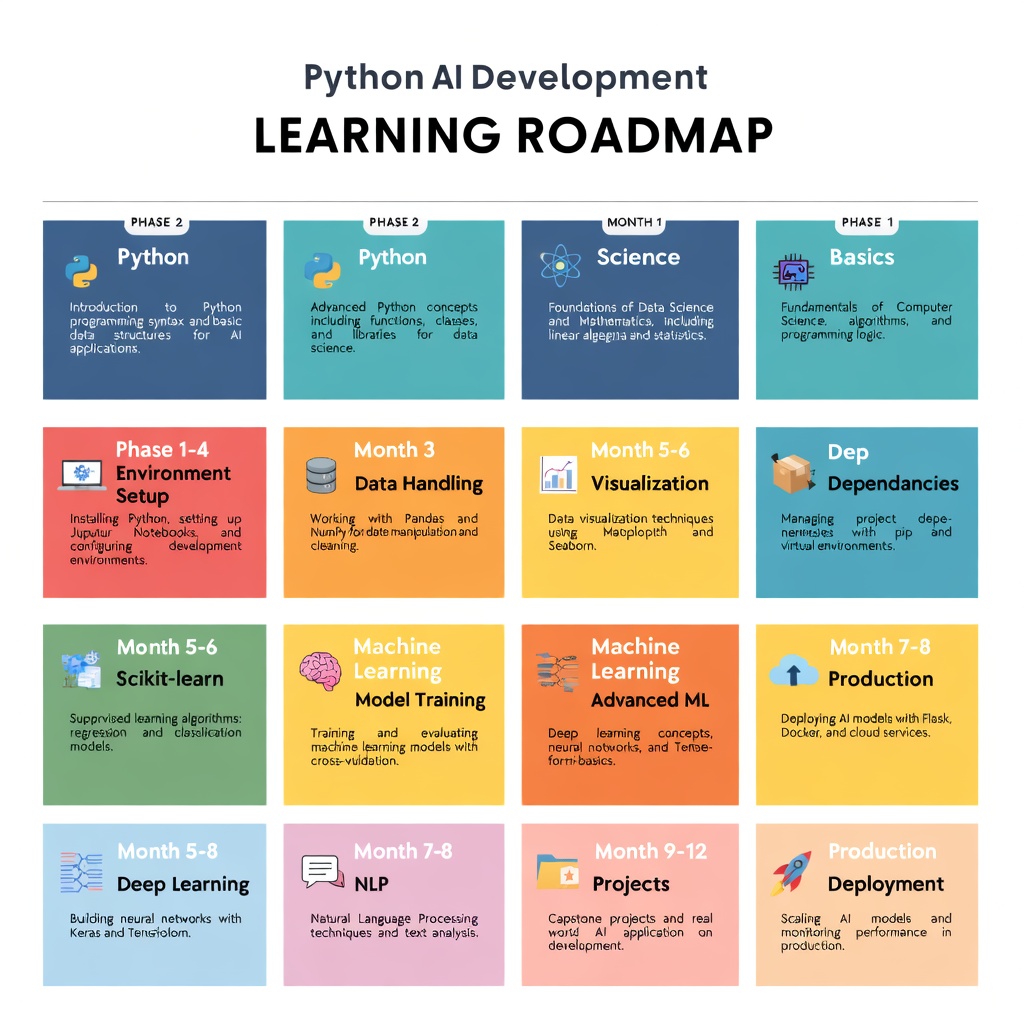
La tabella di marcia è semplice:
Mese 1-2: padroneggia le nozioni di base di Python e la configurazione dell'ambiente. Crea un progetto di esplorazione dei dati.
Mese 3-4: Impara NumPy, Pandas, visualizzazione. Costruisci una pipeline di dati.
Mese 5-6: impara scikit-learn. Costruisci un modello predittivo.
Month 7-8: Learn PyTorch or TensorFlow. Riprodurre documenti di ricerca.
Mese 9-12: impara LangChain. Costruisci agenti. Distribuisci in produzione.
Questo ritmo è ambizioso ma realizzabile. La chiave è la coerenza piuttosto che l’intensità. Un'ora al giorno batte ogni volta un corso accelerato del fine settimana.
Inizia oggi. Scegli un piccolo progetto: automatizza qualcosa, analizza qualcosa che ti interessa, crea qualcosa di utile. Quindi ridimensiona da lì.
Pronto a padroneggiare lo sviluppo dell'intelligenza artificiale? Unisciti alla comunità learnAI → comunità learnAI Skool