Python para el desarrollo de IA: guía completa para principiantes 2026

⏱ Lectura de 25 minutos · Categoría: Desarrollo de IA
Introducción
Python es el lenguaje de la IA. Desde los laboratorios de investigación de OpenAI hasta los sistemas de producción de Google, Python impulsa la revolución de la IA. Si desea crear aplicaciones de IA, Python no es negociable.
Pero aprender Python para IA no es como aprender Python para desarrollo web. Necesita bibliotecas, marcos y modelos mentales específicos. La mayoría de los principiantes comienzan con cursos teóricos y se pierden en las matemáticas antes de escribir una sola línea de código que produzca resultados reales.
Esta guía adopta un enfoque diferente. Aprenderá Python para IA de la misma manera que los profesionales construyen sistemas: de forma práctica, centrado en proyectos, con la teoría suficiente para comprender lo que sucede bajo el capó.
Al final, comprenderá el ecosistema de IA de Python, escribirá código funcional que utilice el aprendizaje automático y las API de IA, y tendrá una hoja de ruta realista hacia la competencia en IA.
Estadística clave: Los desarrolladores que aprenden a través de la construcción tardan entre 6 y 12 meses en alcanzar la competencia profesional. Quienes se centran en cursos primero tardan entre 18 y 24 meses. ¿La diferencia? Aplicación inmediata.
Tabla de contenidos
- Por qué Python para la IA: la ventaja del ecosistema
- Configuración del entorno de desarrollo de IA de Python
- Conceptos básicos de Python para IA
- Bibliotecas Python esenciales para IA
- Marcos de aprendizaje profundo: PyTorch vs TensorFlow
- Trabajar con modelos previamente entrenados
- Creación de su primera aplicación de IA
- LangChain: creación de agentes inteligentes
- Preparación y preprocesamiento de datos
- Del prototipo a la producción
- Errores comunes y cómo evitarlos
- Preguntas frecuentes
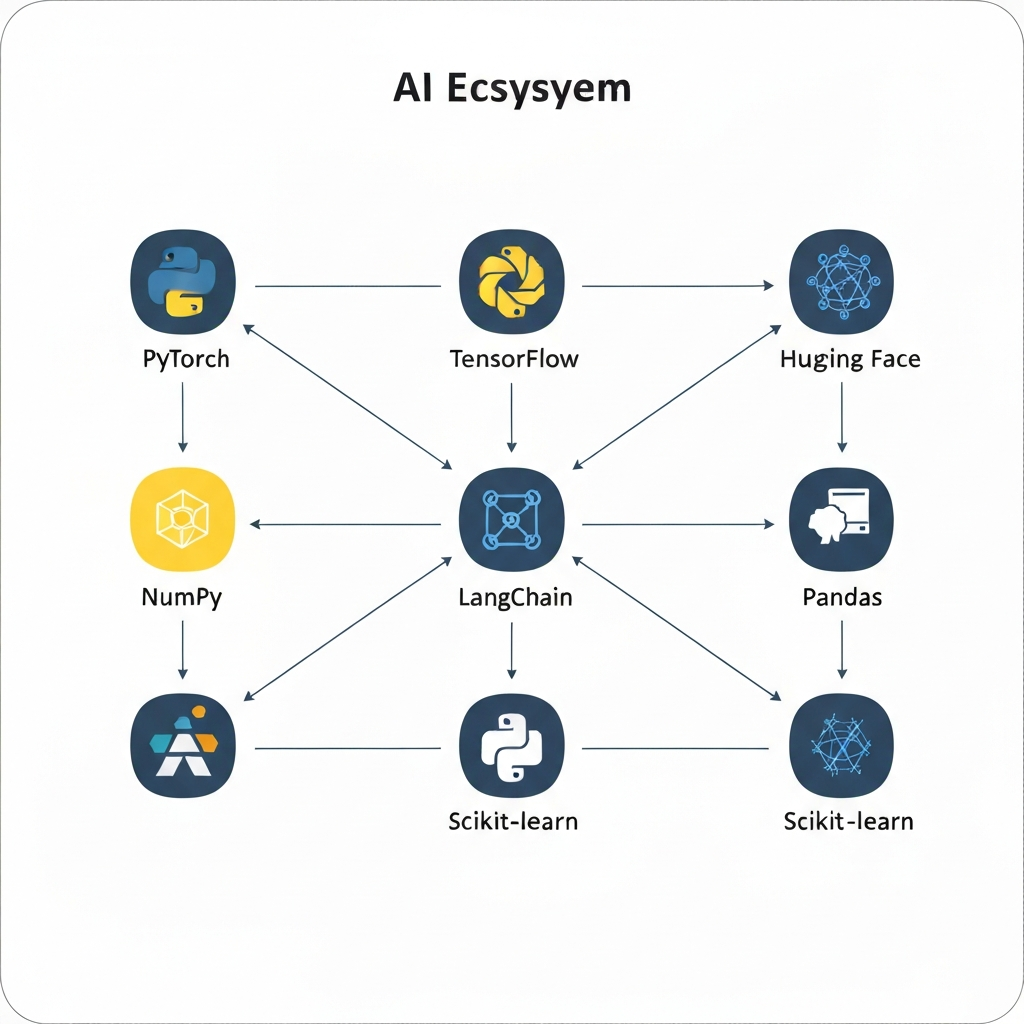
Por qué Python para la IA: la ventaja del ecosistema
Python no es el lenguaje más rápido. No es el más elegante. Pero domina la IA por una razón: el ecosistema.
El Ecosistema
Todos los principales marcos de IA dan prioridad a Python:
- PyTorch: investigación y producción de aprendizaje profundo
- TensorFlow: aprendizaje automático escalable a escala empresarial
- Hugging Face: más de 1 millón de modelos previamente entrenados para texto, visión y audio
- LangChain: creación de agentes inteligentes con LLM
- SDK de OpenAI Python: API oficiales para GPT-4, incrustaciones y más
Cuando se produce un nuevo avance en la IA (una nueva arquitectura de modelo, una nueva técnica de entrenamiento), la primera implementación siempre es en Python.
La comunidad
La comunidad de IA es la primera en Python. Respuestas de Stack Overflow, proyectos de GitHub, artículos de investigación con código: todos son Python. Cuando te quedas atascado, la ayuda es abundante.
La curva de velocidad a prototipo
Python sacrifica la velocidad de ejecución por la velocidad de desarrollo. Una tarea que lleva semanas en Java lleva días en Python. Para la IA, esta compensación vale la pena. Dedicas el 90% de tu tiempo a algoritmos y arquitectura, y el 10% a la optimización del rendimiento.
Configuración de su entorno de desarrollo de IA en Python

No necesitas hardware costoso para comenzar. Una computadora portátil MacBook o Windows está bien. Si tienes una GPU (preferiblemente NVIDIA), mejor aún, pero no es necesaria para aprender.
Paso 1: instalar Python
Descargue Python 3.12 o 3.13, 3.14 desde python.org. Evite la versión 3.15+ (demasiado nueva, algunos paquetes se retrasan).
# Verificar instalación
Python --versión
# Debería generar: Python 3.12.x o 3.14.xPaso 2: crear un entorno virtual
Nunca instale paquetes globalmente. Utilice siempre entornos virtuales.
# Crear entorno
python -m venv myai_env
# Activar (Mac/Linux)
fuente myai_env/bin/activate
# Activar (Windows)
myai_env\Scripts\activar
# Su terminal ahora debería mostrar (myai_env)Paso 3: Instalar paquetes esenciales
pip install numpy pandas matplotlib scikit-learn jupyterPaso 4: Instalar AI Frameworks
Para aprender, comience con PyTorch (más fácil para principiantes):
# versión de CPU (recomendado para principiantes)
pip instalar antorcha torchvision torchaudio
# Versión de GPU (si tienes GPU NVIDIA)
pip instalar antorcha torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118Paso 5: configura tu IDE
Utilice:
- VS Code + extensión Python (gratuita, recomendada)
- Comunidad PyCharm (funciones gratuitas específicas de IA)
- Cursor (codificación asistida por IA, 20 USD al mes)
Paso 6: Verificar la configuración
python -c "importar antorcha; imprimir(torch.__version__)"Deberías ver un número de versión impreso.
Conclusión clave: La configuración del entorno tarda 30 minutos. Invierta este tiempo una vez; ahorrará horas después.
Conceptos básicos de Python para IA

No es necesario ser un experto en Python. Necesitas entender estos cinco conceptos:
Concepto 1: Variables y Tipos
# Números
edad = 25 # entero
altura = 5,9 # flotador
puntuación = 98,5
# Cadenas
nombre = "Alicia"
mensaje = f"Hola, {nombre}" # cadenas f para formatear
# Listas (ordenadas, modificables)
números = [1, 2, 3, 4, 5]
números.añadir(6)
# Diccionarios (pares clave-valor)
persona = {"nombre": "Alice", "edad": 25, "ciudad": "NYC"}
print(persona["nombre"]) # Acceso: AliceConcepto 2: Funciones
def saludar(nombre):
return f"¡Hola, {nombre}!"
resultado = saludar("Alice") # Las funciones toman entrada y devuelven salidaConcepto 3: Bibliotecas e Importaciones
# Importar biblioteca completa
importar numpy como np
# Importar función específica
desde fecha y hora importar fecha y hora
# Usa lo que importaste
matriz = np.matriz([1, 2, 3, 4, 5])
ahora = datetime.now()Concepto 4: Comprensiones de listas (taquigrafía Pythonic)
# Bucle tradicional al cuadrado = [] para el número en [1, 2, 3, 4, 5]: cuadrado.append(número ** 2) # Manera pitónica al cuadrado = [número ** 2 para el número en [1, 2, 3, 4, 5]] # Ambos producen: [1, 4, 9, 16, 25]
Concepto 5: Manejo de errores
intenta:
resultado = 10/0 # Esto fallará
excepto ZeroDivisionError:
print("¡No se puede dividir por cero!")
finalmente:
print("El código de limpieza se ejecuta independientemente")Conclusión clave: domina estos cinco conceptos y podrás escribir el 80 % del código de IA que encontrarás.
Bibliotecas Python esenciales para IA
NumPy: La Fundación
NumPy crea matrices y matrices: la estructura de datos de toda la IA.
importar numpy como np
# Crear matrices
matriz = np.matriz([1, 2, 3, 4, 5])
matriz = np.array([[1, 2, 3], [4, 5, 6]])
# Operaciones sobre matrices
media = np.media (matriz) # Promedio
std = np.std(matriz) # Desviación estándar
normalizado = (matriz - media) / std # NormalizarPandas: manipulación de datos
Pandas se encarga de la carga, limpieza y exploración de datos.
importar pandas como pd
# Cargar CSV
df = pd.read_csv('datos.csv')
# Explorar
df.head() # Primeras 5 filas
df.describe() # Estadísticas
df.info() # Tipos de datos y valores faltantes
# limpio
df = df.dropna() # Eliminar valores faltantes
df['age'] = df['age'].astype(int) # Convertir tipos
# Filtro
gente_joven = df[df['edad'] < 30]Matplotlib y Seaborn: Visualización
No puedes depurar lo que no puedes ver.
importar matplotlib.pyplot como plt
importar seaborn como sns
# Trama lineal
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
plt.xlabel('X')
plt.ylabel('Y')
plt.mostrar()
# Histograma
sns.histplot(datos=df, x='edad', bins=20)
plt.show()Scikit-Learn: aprendizaje automático clásico
Para tareas que no requieren aprendizaje profundo, scikit-learn es el más rápido.
de sklearn.linear_model importar LinearRegression
desde sklearn.model_selection importar train_test_split
# Dividir datos
X_train, X_test, y_train, y_test = tren_test_split(
características, etiquetas, test_size=0.2
)
# Modelo de tren
modelo = Regresión Lineal()
modelo.fit(X_train, y_train)
# Evaluar
puntuación = model.score(X_test, y_test)Marcos de aprendizaje profundo: PyTorch vs TensorFlow
Ambos son excelentes. PyTorch es más amigable para principiantes. TensorFlow es mejor para la escala de producción.
PyTorch: la elección de investigación
El código PyTorch se lee como Python normal. Los errores son claros. La curva de aprendizaje es suave.
importar antorcha
importar torch.nn como nn
# Crea una red neuronal simple
clase SimpleNet(nn.Módulo):
def __init__(yo):
super().__init__()
self.fc1 = nn.Linear(784, 128) # 784 entradas → 128 neuronas
self.fc2 = nn.Linear(128, 10) # 128 neuronas → 10 salidas
def adelante(yo, x):
x = antorcha.relu(self.fc1(x))
x = yo.fc2(x)
volver x
# Crear una instancia
modelo = SimpleNet()
# Pase hacia adelante
input_data = torch.randn(32, 784) # 32 muestras, 784 características
salida = modelo(input_data)TensorFlow: la elección de producción
TensorFlow escala a GPU y conjuntos de datos masivos. Más ceremonia, pero más control.
importar tensorflow como tf
# Crear modelo
modelo = tf.keras.Sequential([
tf.keras.layers.Dense(128, activación='relu', input_shape=(784,)),
tf.keras.layers.Dense(10, activación='softmax')
])
# compilar
modelo.compilar(
optimizador = 'adam',
pérdida='sparse_categorical_crossentropy',
métricas=['precisión']
)
# tren
model.fit(X_train, y_train, épocas=10)Conclusión clave: Comience con PyTorch para aprender. Cambie a TensorFlow si necesita realizar una implementación a escala empresarial.
Trabajar con modelos previamente entrenados
Entrenar modelos desde cero es lento y costoso. Los modelos previamente entrenados son mucho más rápidos.
Transformers de cara abrazada
Hugging Face alberga más de 1 millón de modelos de código abierto.
desde el canal de importación de transformadores
# Generación de texto
generador = canalización ('generación de texto', modelo = 'gpt2')
resultado = generador('Érase una vez', max_length=50)
imprimir (resultado)
# Análisis de sentimiento
clasificador = canalización ('análisis de sentimiento')
resultado = clasificador ("¡Me encanta esta película!")
# Salida: [{'label': 'POSITIVO', 'puntuación': 0,9999}]
# Reconocimiento de entidad nombrada
ner = tubería('ner')
resultado = ner("Apple Inc tiene su sede en Cupertino, California")
# Extrae organizaciones, ubicaciones y personasAPI OpenAI (GPT-4, incrustaciones)
Se puede acceder a los modelos más potentes a través de API.
desde openai importar OpenAI
cliente = OpenAI(api_key="tu-clave-api")
# Generar texto
respuesta = cliente.chat.compleciones.create(
modelo="gpt-4",
mensajes=[
{"role": "usuario", "content": "Explica la computación cuántica en 2 oraciones"}
]
)
print(respuesta.opciones[0].message.content)Ajuste de modelos preentrenados
Adapte los modelos a su dominio específico.
desde transformadores importa Trainer, TrainingArguments
Training_args = Argumentos de entrenamiento(
salida_dir='./resultados',
num_train_epochs=3,
per_device_train_batch_size=16,
)
entrenador = entrenador (
modelo = modelo,
args=args_entrenamiento,
train_dataset=train_dataset,
)
entrenador.train()Creación de su primera aplicación de IA
Creemos un analizador de opiniones que clasifique las reseñas de películas.
Paso 1: Obtener datos
importar pandas como pd
# Cargar datos de muestra
datos = {
'revisión': [
'¡Esta película es increíble!',
"Terrible pérdida de tiempo",
"No está mal, vale la pena verlo"
],
'sentimiento': &['positivo', 'negativo', 'positivo']
}
df = pd.DataFrame(datos)Paso 2: cargar el modelo previamente entrenado
desde el canal de importación de transformadores
clasificador = canalización ('análisis de sentimiento')Paso 3: hacer predicciones
revisiones = df['review'].tolist()
predicciones = clasificador (reseñas)
# Agregar al marco de datos
df['sentimiento_predicho'] = [
pred['label'].lower() para pred en predicciones
]
imprimir(df)Paso 4: Evaluar
# Comparar lo previsto con lo real
precisión = (df['sentiment'] == df['predicted_sentiment']).mean()
print(f"Precisión: {precisión:.2%}")Conclusión clave: Todo este flujo de trabajo (cargar datos, hacer predicciones, evaluar) requirió 20 líneas de código. Este es el poder de los modelos previamente entrenados.
LangChain: creación de agentes inteligentes
LangChain conecta los LLM con herramientas externas. Esto permite a los agentes buscar en la web, leer archivos PDF y ejecutar código.
Cadena LLM Básica
desde langchain.chat_models importar ChatOpenAI
desde langchain.prompts importar ChatPromptTemplate
llm = ChatOpenAI(modelo="gpt-4", temperatura=0)
# Crear mensaje
indicador = ChatPromptTemplate.from_messages([
("usuario", "Explique {tema} en 2 oraciones")
])
# Crear cadena
cadena = mensaje | llm
# Ejecutar
resultado = chain.invoke({"tema": "aprendizaje automático"})
imprimir(resultado.contenido)Agente con Herramientas
desde langchain.agents importe inicialize_agent, herramienta de la herramienta de importación langchain.tools desde langchain.chat_models importar ChatOpenAI @herramienta calculadora def(expresión: str) -> cadena: """Evalúa expresiones matemáticas""" devolver str(eval(expresión)) @herramienta def web_search(consulta: str) -> cadena: """Busca en la web""" # Implementar con la biblioteca de solicitudes. devolver f"Resultados de {consulta}" herramientas = [calculadora, web_search] llm = ChatOpenAI(modelo="gpt-4") agente = inicializar_agente(herramientas, llm, agente="zero-shot-react-description") result = agent.run("¿Qué es 2+2? Luego busque la capital de Francia")
Este agente elige qué herramientas utilizar y en qué orden: de forma totalmente autónoma.
Preparación y preprocesamiento de datos
La mayoría de los proyectos de IA dedican el 70 % del tiempo a la preparación de datos. Aprenda esta habilidad temprano.
Cargando datos
importar pandas como pd
#CSV
df = pd.read_csv('datos.csv')
# JSON
df = pd.read_json('datos.json')
#base de datos SQL
importar sqlite3
conexión = sqlite3.connect('base de datos.db')
df = pd.read_sql('SELECT * FROM table', conexión)Datos de limpieza
# Eliminar valores faltantes
df = df.dropna()
# Completar los valores faltantes
df['edad'].fillna(df['edad'].mean(), inplace=True)
# Eliminar duplicados
df = df.drop_duplicates()
# Eliminar valores atípicos (valores superiores a 3 desarrolladores estándar)
df = df[
(df['edad'] > df['edad'].mean() - 3 * df['edad'].std()) &
(df['edad'] < df['edad'].media() + 3 * df['edad'].std())
]Ingeniería de funciones
# Crear nuevas funciones
df['edad_cuadrado'] = df['edad'] ** 2
df['age_category'] = pd.cut(df['age'], bins=[0, 18, 65, 100])
# Codificar variables categóricas
df = pd.get_dummies(df, columnas=['ciudad'])
# Escalar características numéricas
desde sklearn.preprocesamiento importar StandardScaler
escalador = Escalador Estándar()
df[['edad', 'ingresos']] = escalar.fit_transform(df[['edad', 'ingresos']])Del prototipo a la producción
Pasar de los cuadernos Jupyter a la producción requiere estructura.
Estructura del proyecto
my_ai_project/ ├── datos/ │ ├── crudo/ │ └── procesado/ ├── modelos/ │ └── modelo_entrenado.pkl ├── cuadernos/ │ └── exploración.ipynb ├── src/ │ ├── __init__.py │ ├── data_loader.py │ ├── modelo.py │ └── predecir.py ├── requisitos.txt └── LÉAME.md
Ejemplo de guión de producción
# src/predict.py importar pepinillo importar pandas como pd clase ModelPipeline: def __init__(self, ruta_modelo): con open(model_path, 'rb') como f: self.modelo = pickle.load(f) def predecir(self, input_data): """input_data: marco de datos de pandas""" predicciones = self.model.predict(input_data) predicciones de retorno si __nombre__ == '__principal__': canalización = ModelPipeline('modelos/trained_model.pkl') test_data = pd.read_csv('datos/procesado/test.csv') predicciones = canalización.predict(test_data) imprimir(predicciones)
Implementación con FastAPI
desde fastapi importar FastAPI
desde pydantic importar modelo base
importar pepinillo
aplicación = FastAPI()
# Cargar el modelo una vez al inicio
con open('models/trained_model.pkl', 'rb') como f:
modelo = pepinillo.carga(f)
clase Solicitud de Predicción (Modelo Base):
edad: int
ingresos: flotación
@app.post("/predecir")
def predecir (solicitud: Solicitud de predicción):
predicción = modelo.predict([[solicitud.edad, solicitud.ingresos]])
return {"predicción": float(predicción[0])}
# Ejecutar: aplicación uvicorn:app --reloadErrores comunes y cómo evitarlos
Error 1: saltar directamente al aprendizaje profundo
El aprendizaje profundo es potente pero excesivo para la mayoría de los problemas. Pruebe scikit-learn primero.
Solución: La regresión lineal, los bosques aleatorios y el aumento de gradiente resuelven el 80 % de los problemas sin aprendizaje profundo.
Error 2: trabajar sin control de versiones
Iterarás constantemente. Sigue tu trabajo.
Solución: Utilice Git desde el primer día. Envíe a GitHub.
git init git agregar. git commit -m "Compromiso inicial" git push origen principal
Error 3: No documentar el código
Olvidarás lo que escribiste en 2 semanas.
Solución: Agregar cadenas de documentación a funciones:
def predict_sentiment(texto): """ Clasifique la opinión del texto como positiva o negativa. Argumentos: text (str): El texto a clasificar Devoluciones: str: 'positivo' o 'negativo' """ # Implementación devolver resultado
Error 4: entrenar con todos tus datos
No puedes evaluar los datos con los que has entrenado. Reserve siempre los datos de la prueba.
Solución: Divide tus datos:
de sklearn.model_selection importar train_test_split
X_train, X_test, y_train, y_test = tren_test_split(
X, y, tamaño_prueba=0.2, estado_aleatorio=42
)Error 5: ignorar el desequilibrio de datos
Si se predice fraude (0,1 % de los casos), se utilizará un modelo que prediga «no fraude»; siempre es 99,9% exacto pero inútil.
Solución: utilice métricas apropiadas (puntuación F1, AUC-ROC) y técnicas de remuestreo.
Preguntas frecuentes
P: ¿Cuánto tiempo lleva aprender Python para IA?
6-12 meses de práctica constante para alcanzar la competencia profesional. Más rápido si construye proyectos inmediatamente. Más lento si miras cursos sin codificar.
P: ¿Necesito una GPU?
No, no para empezar. La CPU de una computadora portátil moderna está bien para aprender. La GPU acelera el entrenamiento para modelos grandes (beneficioso una vez que comprendes los conceptos básicos).
P: ¿Debería aprender primero matemáticas o codificación?
Primero codificar. Aprende matemáticas a medida que las encuentres. La teoría sin práctica se olvida rápidamente.
P: ¿Cuál es el mejor orden para aprender sobre bibliotecas?
NumPy → Pandas → Matplotlib → Scikit-Learn → PyTorch (o TensorFlow) → LangChain.
P: ¿Cómo sé si estoy listo para la producción?
Estarás listo cuando puedas:
1. Cargue y limpie datos de forma independiente
2. Entrene un modelo sin copiar y pegar código
3. Evaluar el desempeño con métricas apropiadas
4. Implementar en una API simple
P: ¿Debo usar Jupyter o VS Code?
Ambos. Jupyter para exploración y aprendizaje. VS Code para proyectos destinados a producción.
P: ¿Cómo puedo mantenerme actualizado con la IA que cambia rápidamente?
Siga: artículos con código, blog Hugging Face y foros fast.ai. Cree proyectos utilizando nuevas herramientas: ese es el aprendizaje más rápido.
Bibliotecas avanzadas de Python para el desarrollo de IA
PyTorch para aprendizaje profundo
PyTorch es el marco preferido para la investigación y la producción de IA. Es Pythonic, flexible y ampliamente adoptado por los principales equipos de IA de Meta, Tesla y OpenAI.
importar antorcha
importar torch.nn como nn
desde torch.utils.data importar DataLoader, TensorDataset
clase SimpleNet(nn.Módulo):
def __init__(self, tamaño_entrada, tamaño_oculto, tamaño_salida):
super(SimpleNet, uno mismo).__init__()
self.fc1 = nn.Linear(tamaño_entrada, tamaño_oculto)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(tamaño_oculto, tamaño_salida)
def adelante(yo, x):
x = yo.fc1(x)
x = self.relu(x)
x = yo.fc2(x)
volver x
modelo = SimpleNet(10, 64, 2)
loss_fn = nn.CrossEntropyLoss()
optimizador = antorcha.optim.Adam(modelo.parametros(), lr=0.001)
para la época en el rango (100):
salidas = modelo (X_train)
pérdida = pérdida_fn(salidas, y_train)
optimizador.zero_grad()
pérdida.hacia atrás()
optimizador.paso()Conclusión clave: PyTorch permite una experimentación rápida. Cambie arquitecturas y funciones de pérdida con solo unas pocas líneas de código.
LangChain para aplicaciones LLM
LangChain simplifica la creación de aplicaciones sobre modelos de lenguaje como GPT-4. Maneja indicaciones, cadenas, memoria e integraciones.
desde langchain importar OpenAI, LLMChain, PromptTemplate llm = OpenAI(api_key="sk-...", temperatura=0.7) template = "Eres un útil asistente de IA. Pregunta del usuario: {pregunta}. Respuesta útil:" mensaje = PromptTemplate(input_variables=["pregunta"], plantilla=plantilla) cadena = LLMChain(llm=llm, mensaje=mensaje) resultado = chain.run("¿Qué es el aprendizaje automático?") imprimir(resultado)
Utilice LangChain para: Chatbots, respuesta a preguntas, resúmenes y cadenas de razonamiento de varios pasos.
Bases de datos vectoriales: Pinecone y Weaviate
Para aplicaciones de IA que utilizan incrustaciones, las bases de datos vectoriales almacenan y consultan incrustaciones de manera eficiente.
importar piña
piña.init(api_key="...", entorno="us-west1-gcp")
índice = piña.Index("documentos")
incrustaciones = [[0.1, 0.2, 0.3], [0.4, 0.5, 0.6]]
identificadores = ["doc1", "doc2"]
index.upsert(vectores=lista(zip(ids, incrustaciones)))
query_embedding = [0,15, 0,25, 0,35]
resultados = index.query(query_embedding, top_k=5)Las bases de datos vectoriales potencian los sistemas de recomendación, la búsqueda semántica y la generación de recuperación aumentada.
Implementación de modelos de IA en producción
Containerización con Docker
Docker empaqueta su código y sus dependencias en un contenedor coherente.
DESDE python:3.11-slim
DIRTRABAJO /aplicación
COPIAR requisitos.txt.
EJECUTAR pip install -r requisitos.txt
COPIAR. .
CMD ["python", "app.py"]Construir y ejecutar:
docker build -t my-ai-app:1.0 .
ventana acoplable ejecutar -p 8000:8000 my-ai-app:1.0Docker garantiza que su modelo funcione de manera idéntica en desarrollo, pruebas y producción.
Implementación de API con FastAPI
FastAPI es rápido y moderno para ofrecer modelos de IA.
desde fastapi importar FastAPI
desde pydantic importar modelo base
importar biblioteca de trabajos
aplicación = FastAPI()
modelo = joblib.load ("modelo.pkl")
clase Solicitud de Predicción (Modelo Base):
características: lista
@app.post("/predecir")
def predecir (solicitud: Solicitud de predicción):
predicción = modelo.predict([solicitud.características])[0]
devolver {"predicción": predicción}Iniciar el servidor:
pip instalar fastapi uvicorn
Aplicación uvicorn: aplicación --host 0.0.0.0 --puerto 8000Cualquier aplicación ahora puede llamar a su modelo: POST http://localhost:8000/predict
Plataformas de implementación (2026)
Hugging Face Spaces: gratuito para modelos de código abierto. Fácil de compartir y hacer demostraciones.
AWS SageMaker: nivel empresarial con escalamiento, monitoreo y control de versiones.
Render o Ferrocarril: implementación sencilla y económica. Comienza en $7/mes.
Google Cloud Run: pago por solicitud, sin servidores. Ideal para cargas de trabajo variables.
Vercel: lo mejor para frontend + IA. Envíe aplicaciones full-stack en minutos.
Probando el código AI
Modelos de pruebas unitarias
Prueba las predicciones de tu modelo con entradas conocidas.
importar prueba unitaria
importar numpy como np
clase TestModel (unittest.TestCase):
configuración def(yo):
self.model = load_model("ruta/al/modelo")
def test_prediction_shape(self):
X = np.array([[1, 2, 3], [4, 5, 6]])
y = auto.modelo.predecir(X)
self.assertEqual(y.forma, (2, 1))
def test_prediction_range(self):
X = np.array([[1, 2, 3]])
y = self.model.predict(X)[0]
self.assertTrue(0 <= y <= 1)
si __nombre__ == '__principal__':
prueba unitaria.main()Seguimiento del rendimiento del modelo
Supervise la precisión del modelo, la latencia y la desviación de datos en producción.
de sklearn.metrics importar precision_score
importar registro
registrador = logging.getLogger(__nombre__)
def monitor_predictions(true_labels, predicciones):
precisión = puntuación_precisión (etiquetas_verdaderas, predicciones)
logger.info(f"Precisión del modelo: {precisión:.4f}")
si la precisión < 0,85:
logger.warning ("¡Precisión del modelo por debajo del umbral!")
precisión de devoluciónErrores comunes en el desarrollo de la IA
Error 1: fuga de datos
Problema: Los datos de prueba incluyen accidentalmente información de los datos de entrenamiento.
# MAL X_normalizado = normalizar(X) X_train, X_test = train_test_split(X_normalizado) # CORRECTO X_train, X_test, y_train, y_test = train_test_split(X, y) X_train = normalizar(X_train) X_test = normalizar(X_test)
Error 2: sobreajuste a conjuntos de datos pequeños
Utilice regularización y validación cruzada.
de sklearn.model_selection importar cross_val_score
de sklearn.linear_model importar LogisticRegression
puntuaciones = cross_val_score(Regresión logística(C=1.0), X, y, cv=5)
print(f"Precisión del CV: {scores.mean():.4f} (+/- {scores.std():.4f})")Error 3: uso de la métrica incorrecta
Para conjuntos de datos desequilibrados, utilice F1 o precisión equilibrada en lugar de precisión.
de sklearn.metrics importe f1_score, balance_accuracy_score
f1 = puntuación_f1(y_verdadero, y_pred)
balance_acc = balance_accuracy_score(y_true, y_pred)Error 4: No se manejan los datos faltantes
de sklearn.impute importar SimpleImputer
imputador = SimpleImputer(estrategia="media")
X_imputed = imputer.fit_transform(X)Ideas de proyectos de IA para el aprendizaje
Proyecto 1: Chatbot de análisis de sentimientos (principiante – 2 semanas)
Crea un chatbot que clasifique los sentimientos y responda.
Herramientas: Transformers, FastAPI, Gradio
Pasos: (1) Usar el modelo de opinión de Hugging Face (2) Crear un punto final FastAPI (3) Crear una interfaz de usuario de Gradio (4) Implementar en espacios de Hugging Face
Habilidades: API de modelo, implementación, integración de UI
Proyecto 2: Motor de recomendación (Intermedio – 4 semanas)
Cree un recomendador de películas mediante filtrado colaborativo.
Herramientas: LightFM, Pandas, PostgreSQL
Pasos: (1) Obtener un conjunto de datos de recomendación (2) Crear un modelo de filtrado colaborativo (3) Crear API (4) Implementar en AWS/Render
Habilidades: Sistemas de recomendación, consultas a bases de datos, diseño de API
Proyecto 3: Sistema de preguntas y respuestas sobre documentos (avanzado – 6 semanas)
Cree un sistema que responda preguntas sobre sus documentos utilizando RAG.
Herramientas: LangChain, OpenAI, Pinecone, FastAPI
Pasos: (1) Cargar y fragmentar documentos (2) Generar incrustaciones, almacenar en Pinecone (3) Recuperar fragmentos para preguntas de los usuarios, llamar a LLM (4) Implementar como aplicación web
Habilidades: LLM, incrustaciones, búsqueda vectorial, implementación de producción
Ruta profesional: de principiante a ingeniero de inteligencia artificial
Meses 1 a 3: Fundaciones
Enfoque: Conceptos básicos de Python, fundamentos de ML, primeros modelos
Acción: Curso de Python (2–3 semanas) → NumPy, Pandas (2 semanas) → proyecto scikit-learn (2 semanas)
Resultado: crear modelos simples de clasificación/regresión
Perspectivas laborales: ingeniero junior de aprendizaje automático, analista de datos (entre 60.000 y 80.000 dólares)
Meses 4 a 6: Aprendizaje profundo
Enfoque: Redes neuronales, PyTorch, modelos de imagen/NLP
Acción: Teoría de redes neuronales (2 semanas) → PyTorch CNN (3 semanas) → NLP Transformers (2 semanas)
Resultado: entrenar e implementar modelos de aprendizaje profundo
Perspectivas laborales: ingeniero de aprendizaje automático, ingeniero de inteligencia artificial (entre 120.000 y 160.000 dólares)
Meses 7 a 12: producción y desarrollo. Especialización
Enfoque: Implementación, LLM, escalamiento, especialización
Acción: Elegir especialización (CV/NLP/recomendaciones) → Crear 2 o 3 proyectos de cartera → Implementar en producción → Contribuir al código abierto
Resultado: enviar productos de IA a producción
Perspectivas laborales: ingeniero sénior de aprendizaje automático, ingeniero de productos de inteligencia artificial (entre 150 000 y 250 000 dólares o más)
Más allá del año 1: dominio y experiencia Liderazgo
Opciones:
– Investigador: Enfoque en doctorado, laboratorios FAANG ($180–300K+)
– Fundador de la startup: crear un producto de inteligencia artificial (entre 0 y 10 millones de dólares o más, alto riesgo)
– Arquitecto de IA: liderar estrategias empresariales de IA (entre 200 000 y 400 000 dólares)
– Científico de IA: modelos Frontier ($200-500K+)
Clave: Cree proyectos reales, envíelos a producción y comprenda el impacto empresarial.
Aplicaciones de IA: ejemplos de Python del mundo real
Ejemplo 1: creación de un chatbot sencillo con LangChain
Aquí tienes un chatbot completo que recuerda el contexto de la conversación:
desde langchain.llms importar OpenAI
desde langchain.memory importar ConversationBufferMemory
de langchain.chains importar ConversationChain
memoria = MemoriaBufferConversación()
llm = OpenAI(api_key="sk-...")
conversación = Cadena de conversación(llm=llm, memoria=memoria)
mientras que Verdadero:
entrada_usuario = entrada("Tú: ")
respuesta = conversación.ejecutar (entrada = entrada_usuario)
print(f"Bot: {respuesta}")Este chatbot mantiene el historial de conversaciones automáticamente. ConversationBufferMemory almacena toda la conversación, por lo que el modelo tiene contexto para preguntas de seguimiento.
Ejemplo 2: Clasificación de imágenes con cara de abrazo
Clasificar imágenes sin entrenar un modelo:
desde el canal de importación de transformadores
clasificador = canalización ("clasificación de imágenes",
modelo="google/vit-base-patch16-224")
resultado = clasificador("ruta/a/imagen.jpg")
imprimir(resultado)Esto descarga un modelo de visión previamente entrenado y clasifica las imágenes en 3 líneas. Ese es el poder de Hugging Face.
Ejemplo 3: extracción de datos de documentos
Utilice IA para extraer datos estructurados de documentos:
desde langchain.llms importar OpenAI
desde langchain.prompts importar PromptTemplate
de langchain.chains importar LLMChain
llm = OpenAI()
plantilla = "Extraiga el monto total, la fecha de la factura y el nombre del cliente de esta factura. Salida como JSON: {invoice_text}"
mensaje = PromptTemplate(input_variables=["texto_factura"], plantilla=plantilla)
cadena = LLMChain(llm=llm, mensaje=mensaje)
resultado = cadena.ejecutar (texto_factura = contenido_factura)
imprimir(resultado)Esto extrae datos estructurados de texto no estructurado sin modelos personalizados.
Optimización del rendimiento para modelos de IA
Reducción del tamaño del modelo: cuantización
Los modelos grandes son lentos. La cuantización convierte pesos de flotantes de 32 bits a enteros de 8 bits, lo que reduce el tamaño 4 veces.
importar antorcha
de transformadores importar AutoModelForSequenceClassification
modelo = AutoModelForSequenceClassification.from_pretrained("bert-base")
cuantificado = torch.quantization.quantize_dynamic(modelo, {torch.nn.Linear}, dtype=torch.qint8)Los modelos cuantificados funcionan entre 2 y 4 veces más rápido con una pérdida de precisión mínima.
Procesamiento por lotes para velocidad
Procesar múltiples entradas a la vez:
# LENTO: uno a la vez
para texto en textos:
resultado = modelo.predecir (texto)
# RÁPIDO: En lotes
resultados = model.predict_batch(textos, tamaño_lote=32)El procesamiento por lotes utiliza la GPU de manera eficiente, lo que acelera las predicciones entre 10 y 50 veces.
Almacenamiento en caché de respuestas de LLM
Guardar llamadas API almacenando en caché:
desde langchain.cache importar InMemoryCache
importar cadena de idiomas
langchain.llm_cache = InMemoryCache()
llm = OpenAI()
resultado1 = llm("¿Qué es la IA?") # llamada API
result2 = llm("¿Qué es la IA?") # Utiliza caché, no requiere llamada APIPara producción, utilice Redis para almacenamiento en caché persistente.
Ejecución de LLM localmente
Ollama: Inferencia LLM local
Ejecute modelos como Llama 2 localmente sin API de nube:
solicitudes de importación importar json def query_local_llm(mensaje): respuesta = request.post("http://localhost:11434/api/generate", json={"modelo": "llama2", "prompt": aviso, "stream": False}) devolver respuesta.json()["respuesta"] resultado = query_local_llm("Explicar el aprendizaje automático") imprimir(resultado)
Beneficios: privacidad, sin costos de API, funciona sin conexión.
Inconveniente: Más lento que la nube, necesita GPU.
Guía de selección de modelos
Empiece poco a poco. Actualice sólo si la calidad es insuficiente.
Depuración de modelos de IA
Usando TensorBoard
Visualiza el entrenamiento en tiempo real:
desde torch.utils.tensorboard importar SummaryWriter
escritor = ResumenEscritor()
para la época en el rango (100):
pérdida = train_one_epoch()
escritor.add_scalar("Pérdida/entrenamiento", pérdida, época)
val_loss = evaluar()
escritor.add_scalar("Pérdida/val", val_loss, época)
escritor.close()Ver: tensorboard --logdir=runs
Explicabilidad del modelo
Comprenda por qué los modelos hacen predicciones:
desde lime.lime_tabular importar LimeTabularExplainer
explicador = LimeTabularExplainer(X_train, modo="clasificación")
exp = explicador.explain_instance(X_test[0], model.predict_proba)
exp.show_in_notebook()LIME muestra qué funciones influyeron más en las predicciones.
Perfil de código
Buscar partes lentas:
importar perfil c
importar pstats
perfilador = cProfile.Profile()
perfilador.enable()
mi_ai_función()
perfilador.disable()
estadísticas = pstats.Stats(perfilador)
stats.sort_stats("acumulativo").print_stats(10)Centrar la optimización en los cuellos de botella.
Seguridad y Privacidad
Protección de datos confidenciales
Nunca envíe datos confidenciales sin procesar a las API. Hash en su lugar:
importar hashlib
def anonymize_user_data(nombre, correo electrónico):
hash = hashlib.sha256(nombre.encode()).hexdigest()
devolver hashLimitación de velocidad
Evitar el agotamiento de la cuota:
de los límites de importación de ratelimit, sleep_and_retry
@sleep_and_retry
@limits(llamadas=100, periodo=60)
def call_api (mensaje):
devolver llm.predict(prompt)Seguridad de claves API
Nunca codifique claves:
importar sistema operativo
desde dotenv importar load_dotenv
cargar_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
llm = OpenAI(api_key=api_key)Almacenar en .env (agregar a .gitignore).
Integración de producción
Consultas de base de datos
importar sqlite3
importar pandas como pd
conexión = sqlite3.connect ("base de datos.db")
df = pd.read_sql_query("SELECCIONAR * DE clientes", conexión)
predicciones = model.predict(df)Registro
importar registro
registro.basicConfig(nivel=registro.INFO)
registrador = logging.getLogger(__nombre__)
prueba:
predicción = modelo.predecir (datos)
logger.info(f"Predicción: {predicción}")
excepto excepción como e:
logger.error(f"Error: {e}")Webhooks para procesamiento de eventos
desde flask importar Flask, solicitar
aplicación = Frasco (__nombre__)
@app.route("/webhook", métodos=["POST"])
definición handle_webhook():
datos = solicitud.json
resultado = ai_model.proceso(datos)
return {"estado": "procesado", "resultado": resultado}
si __nombre__ == "__principal__":
aplicación.run(puerto=5000)Los sistemas externos pueden PUBLICAR eventos en su servicio de IA.
Recursos de aprendizaje recomendados
Sitios web principales
- Hugging Face Hub (huggingface.co): más de 1 millón de modelos previamente entrenados
- Tutoriales oficiales de PyTorch (pytorch.org): fundamentos del aprendizaje profundo
- Fast.ai (fast.ai): Cursos prácticos de aprendizaje profundo
- Papers with Code (paperswithcode.com): Investigación + implementaciones
Comunidades
- r/MachineLearning: comunidad activa de Reddit
- Kaggle: competiciones y conjuntos de datos
- GitHub: proyectos de código abierto
- Servidores de Discord: únete a comunidades de IA
Ideas de proyectos para 2026
- Ajusta Llama 2 en los datos de tu dominio
- Crea un chatbot RAG con Pinecone + LangChain
- Implementar un modelo de visión por computadora en AWS SageMaker
- Crear una API de análisis de sentimiento con FastAPI
- Crear un motor de recomendaciones con filtrado colaborativo
El camino hacia el dominio es realizar proyectos reales.
Preguntas frecuentes
P1: ¿Cuánto tiempo lleva aprender Python para IA?
R: 4 a 8 semanas para lo básico. De 3 a 6 meses para el aprendizaje profundo. 1 a 2 años para estar listo para trabajar (15 a 20 horas por semana).
P2: ¿Necesito un título en matemáticas?
R: No. Las habilidades prácticas son lo más importante. Aprenderás matemáticas en el trabajo si es necesario.
P3: ¿Cuál es el mejor primer proyecto?
R: Entrene un modelo con datos públicos, haga predicciones, evalúe resultados. Kaggle es perfecto para esto.
P4: ¿PyTorch o TensorFlow?
R: PyTorch. Más fácil de aprender, más intuitivo, dominará en 2026.
Construcción de sistemas de IA listos para la producción
Gestión de la deuda técnica
A medida que crecen los proyectos, se acumula la deuda técnica. Administrelo proactivamente.
Fuentes comunes:
– Código escrito rápidamente sin documentación
– Casos extremos mal probados
– Valores codificados y números mágicos
– Dependencias obsoletas
Administrar por:
– Escribir pruebas temprano (no después)
– Documente mientras codifica (comentarios, cadenas de documentos)
– Refactorice periódicamente (dedique entre el 10 y el 20 % del tiempo del sprint)
– Actualizar dependencias mensualmente
– Revisiones de código (detectar problemas antes de que se multipliquen)
Escalado de servicios de IA
Cuando se te queda pequeño un único servidor:
docker build -t my-ai:1.0 .
ventana acoplable empuja mi-ai: 1.0
kubectl apply -f implementación.yaml # Implementar en KubernetesKubernetes organiza contenedores y gestiona el escalado automáticamente.
Opción avanzada: utilizar sin servidor (AWS Lambda, Google Cloud Run). Pague solo por la computación que utilice.
Monitoreo de la IA en producción
Monitorear más allá de las métricas tradicionales:
importar prometheus_client como fiesta de graduación
model_accuracy = prom.Gauge('model_accuracy', 'Precisión del modelo actual')
inference_latency = prom.Histogram('inference_ms', 'Latencia de inferencia')
predicción_volumen = prom.Counter('predicciones_total', 'Predicciones totales')
# Actualizar métricas
model_accuracy.set(0.92)
inferencia_latencia.observar(150)
predicción_volumen.inc()Alerta en:
– Precisión del modelo < umbral
– Latencia de inferencia> línea de base
– Errores de API > 1%
– Deriva de datos (datos nuevos ≠ datos de entrenamiento)
Construyendo su base de IA
La pirámide de habilidades esenciales
[Avanzado: IA de grado de investigación]
/ [Production ML: Implementación y actualización Monitorear]
/ [Core ML: modelos y modelos Algoritmos]
/ [Fundamentos y funciones de Python Bibliotecas]
/ [Conceptos básicos de informática: algoritmos y métodos Estructuras de datos]No es necesario dominar la IA de grado de investigación para crear sistemas de producción. La mayoría de los trabajos necesitan las capas 2 y 3.
Compromiso de tiempo para cada nivel
- Nivel 1 (Conceptos básicos de informática): 3 a 4 semanas
- Nivel 2 (Python + Bibliotecas): 4 a 8 semanas
- Nivel 3 (ML básico): 8 a 16 semanas
- Nivel 4 (Producción ML): 16 a 24 semanas
- Nivel 5 (IA de investigación): más de 2 años de estudio de nivel de doctorado
La mayoría de los profesionales operan en los niveles 2 a 4.
Conclusión: Su camino a seguir
Ahora comprende Python para IA, el ecosistema, las bibliotecas clave, ejemplos prácticos, pruebas, implementación y trayectorias profesionales.
Próximos pasos:
1. Esta semana: configure el entorno Python y ejecute un modelo simple
2. La próxima semana: cree un pequeño proyecto (análisis de sentimiento, recomendación)
3. El próximo mes: impleméntelo en producción (AWS, Heroku o sin servidor)
4. Este trimestre: completar un proyecto de cartera y crear una prueba de trabajo pública
5. Este año: Contribuya al código abierto y obtenga el primer rol o cliente de IA
La barrera de entrada es baja. La ventaja es enorme. Empiece hoy.
P5: ¿Cómo me mantengo actualizado?
R: Lea artículos de arXiv, siga a investigadores, cree proyectos, tome cursos. Dedica entre 1 y 2 horas a la semana.
Conclusión
Python para IA no es difícil. Es una habilidad que se puede aprender y que abre puertas para construir el futuro.
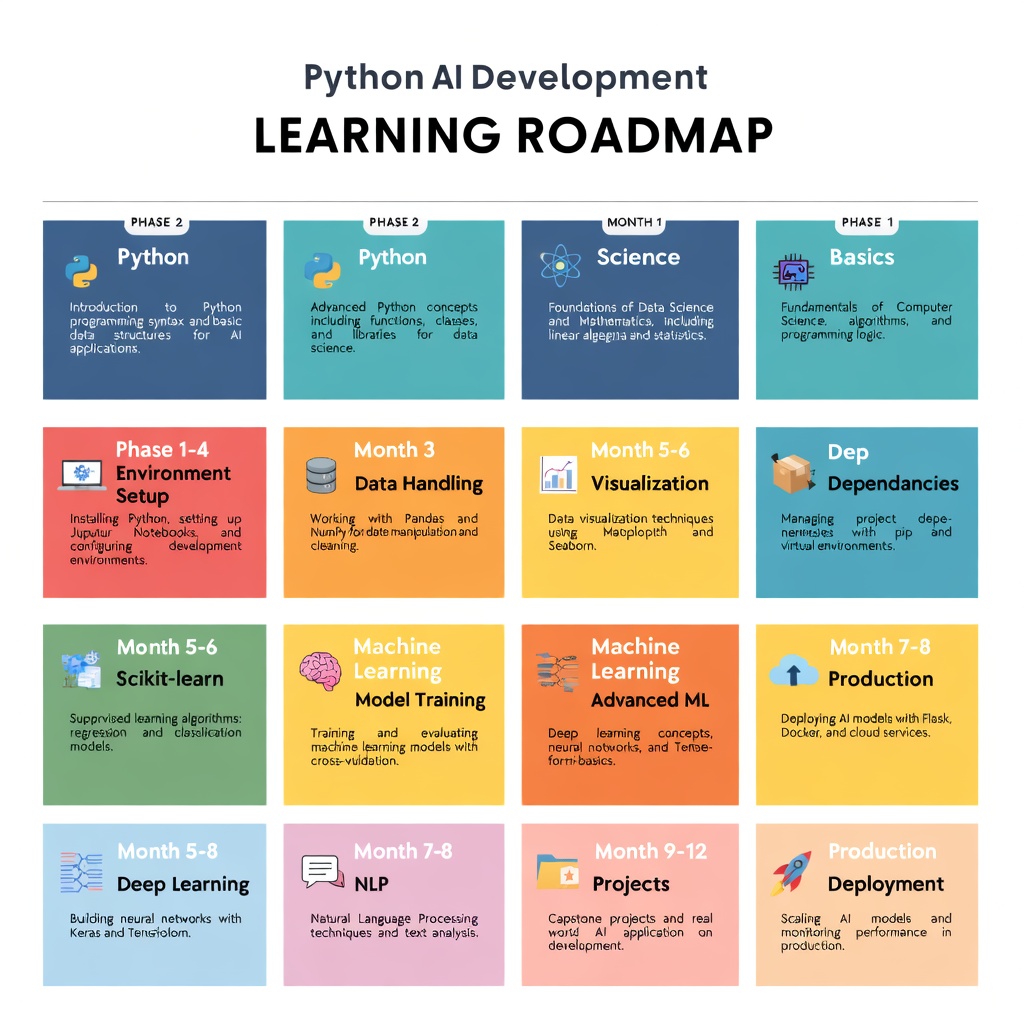
La hoja de ruta es sencilla:
Mes 1-2: Domine los conceptos básicos de Python y la configuración del entorno. Cree un proyecto de exploración de datos.
Mes 3-4: Aprenda NumPy, Pandas y visualización. Cree una canalización de datos.
Mes 5-6: Aprenda scikit-learn. Construya un modelo predictivo.
Mes 7-8: Aprenda PyTorch o TensorFlow. Reproducir trabajos de investigación.
Mes 9-12: Aprenda LangChain. Agentes de construcción. Implementar en producción.
Este ritmo es ambicioso pero alcanzable. La clave es la consistencia sobre la intensidad. Una hora diaria siempre supera a un curso intensivo de fin de semana.
Empiece hoy. Elija un proyecto pequeño: automatice algo, analice algo que le interese, cree algo útil. Luego escale desde allí.
¿Listo para dominar el desarrollo de la IA? Únete a la comunidad learnAI → Comunidad learnAI Skool